3DInAction: Understanding Human Actions in 3D Point Clouds
 Highlight
Highlight
{kind=link}
Abstract
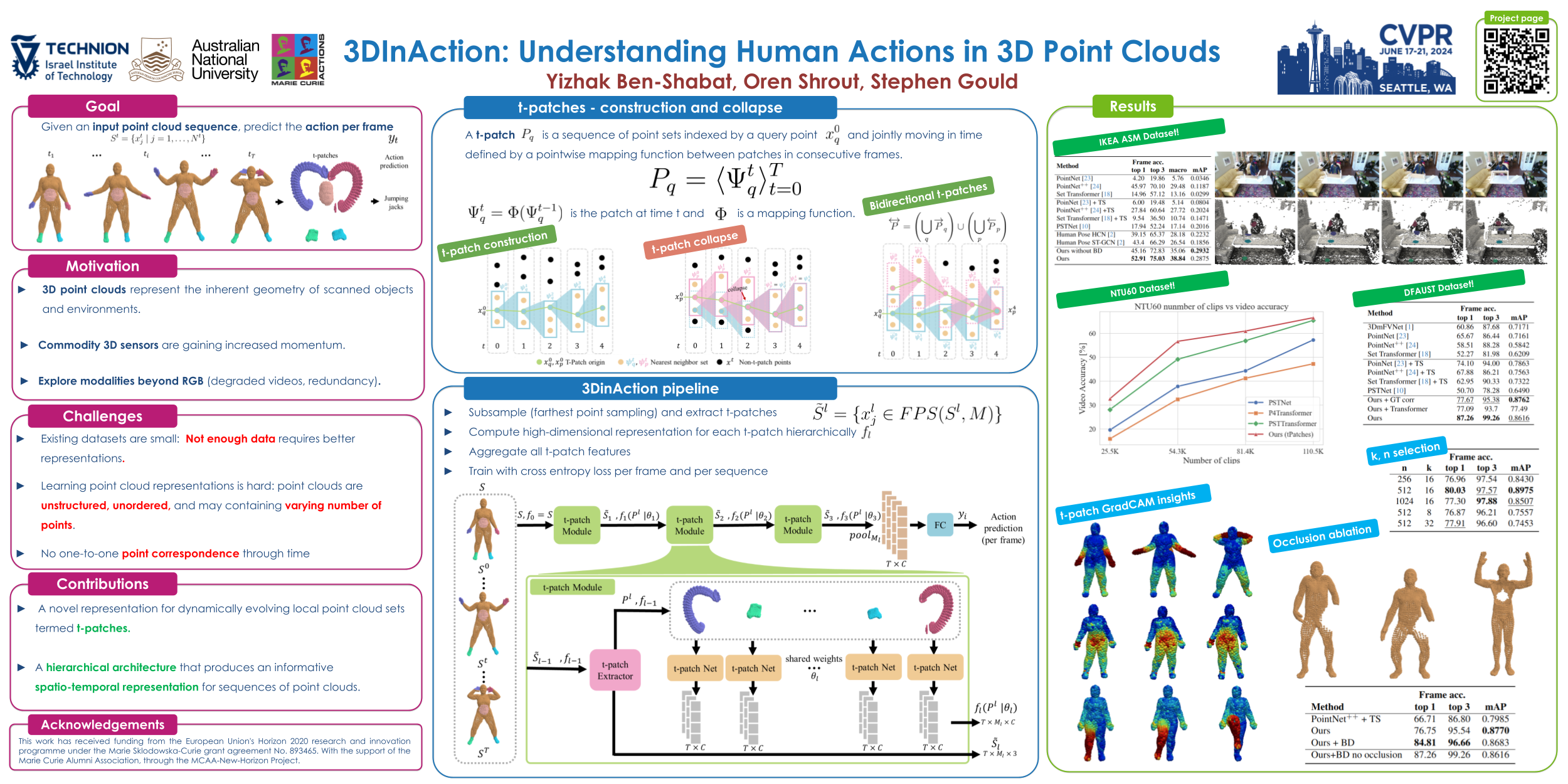
We propose a novel method for 3D point cloud action recognition. Understanding human actions in RGB videos has been widely studied in recent years, however, its 3D point cloud counterpart remains under-explored. This is mostly due to the inherent limitation of the point cloud data modality---lack of structure, permutation invariance, and varying number of points---which makes it difficult to learn a spatio-temporal representation. To address this limitation, we propose the 3DinAction pipeline that first estimates patches moving in time (t-patches) as a key building block, alongside a hierarchical architecture that learns an informative spatio-temporal representation. We show that our method achieves improved performance on existing datasets, including DFAUST and IKEA ASM.Code is publicly available at https://github.com/sitzikbs/3dincaction