From-Ground-To-Objects: Coarse-to-Fine Self-supervised Monocular Depth Estimation of Dynamic Objects with Ground Contact Prior
{kind=link}
Abstract
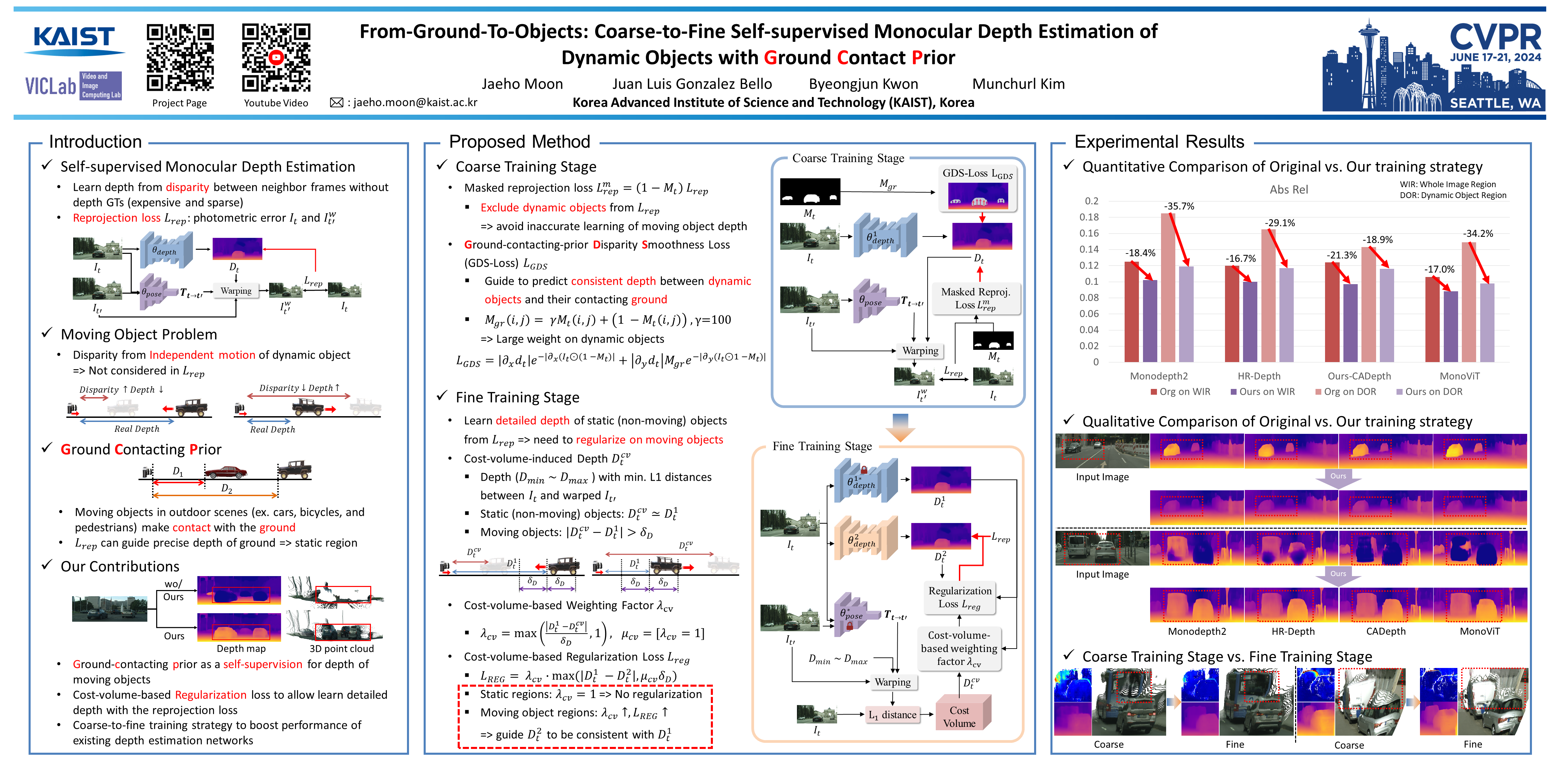
Self-supervised monocular depth estimation (DE) is an approach to learning depth without costly depth ground truths. However, it often struggles with moving objects that violate the static scene assumption during training. To address this issue, we introduce a coarse-to-fine training strategy leveraging the ground contacting prior based on the observation that most moving objects in outdoor scenes contact the ground. In the coarse training stage, we exclude the objects in dynamic classes from the reprojection loss calculation to avoid inaccurate depth learning. To provide precise supervision on the depth of the objects, we present a novel Ground-contacting-prior Disparity Smoothness Loss (GDS-Loss) that encourages a DE network to align the depth of the objects with their ground-contacting points. Subsequently, in the fine training stage, we refine the DE network to learn the detailed depth of the objects from the reprojection loss, while ensuring accurate DE on the moving object regions by employing our regularization loss with a cost-volume-based weighting factor. Our overall coarse-to-fine training strategy can easily be integrated with existing DE methods without any modifications, significantly enhancing DE performance on challenging Cityscapes and KITTI datasets, especially in the moving object regions.