Customization Assistant for Text-to-Image Generation
{kind=link}
Abstract
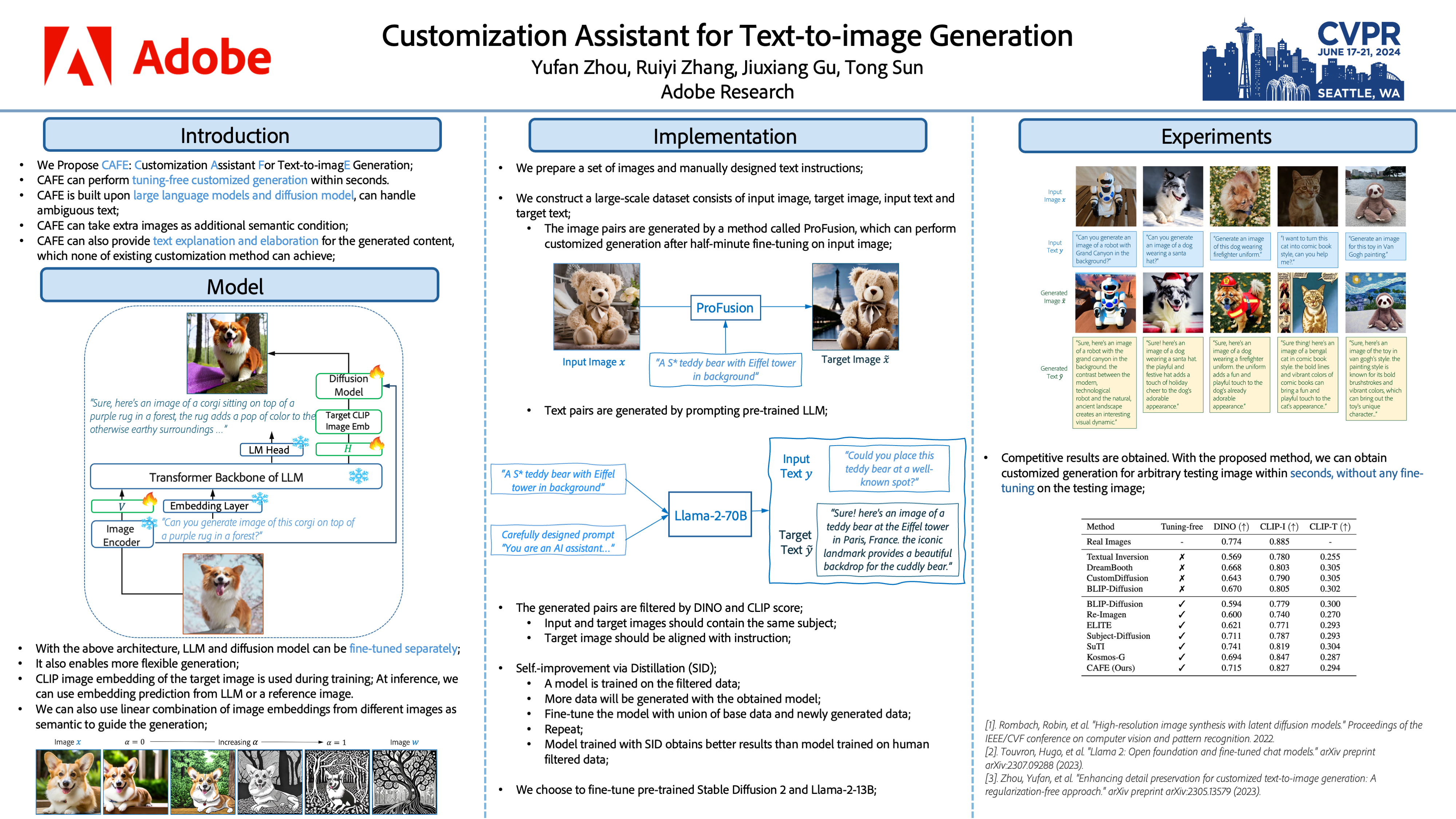
Customizing pre-trained text-to-image generation model has attracted massive research interest recently, due to its huge potential in real-world applications. Although existing methods are able to generate creative content for a novel concept contained in single user-input image, their capability are still far from perfection. Specifically, most existing methods require fine-tuning the generative model on testing images. Some existing methods does not require fine-tuning, while their performance are unsatisfactory. Furthermore, the interaction between users and models are still limited to directive and descriptive prompts such as instructions and captions. In this work, we built a customization assistant based on pre-trained large language model and diffusion model, which can not only perform customized generation in a tuning-free manner within few seconds, but also enable more user-friendly interactions: users can chat with the assistant and input either ambiguous text or clear instruction. Specifically, we propose a new framework consists of a new model design and a novel training strategy with self-distillation. The resulting assistant can perform customized generation in2-5 seconds without any test time fine-tuning. Extensive experiments are conducted, competitive results have been obtained across different domains, illustrating the effectiveness of the proposed method.