Dual Memory Networks: A Versatile Adaptation Approach for Vision-Language Models
{kind=link}
Abstract
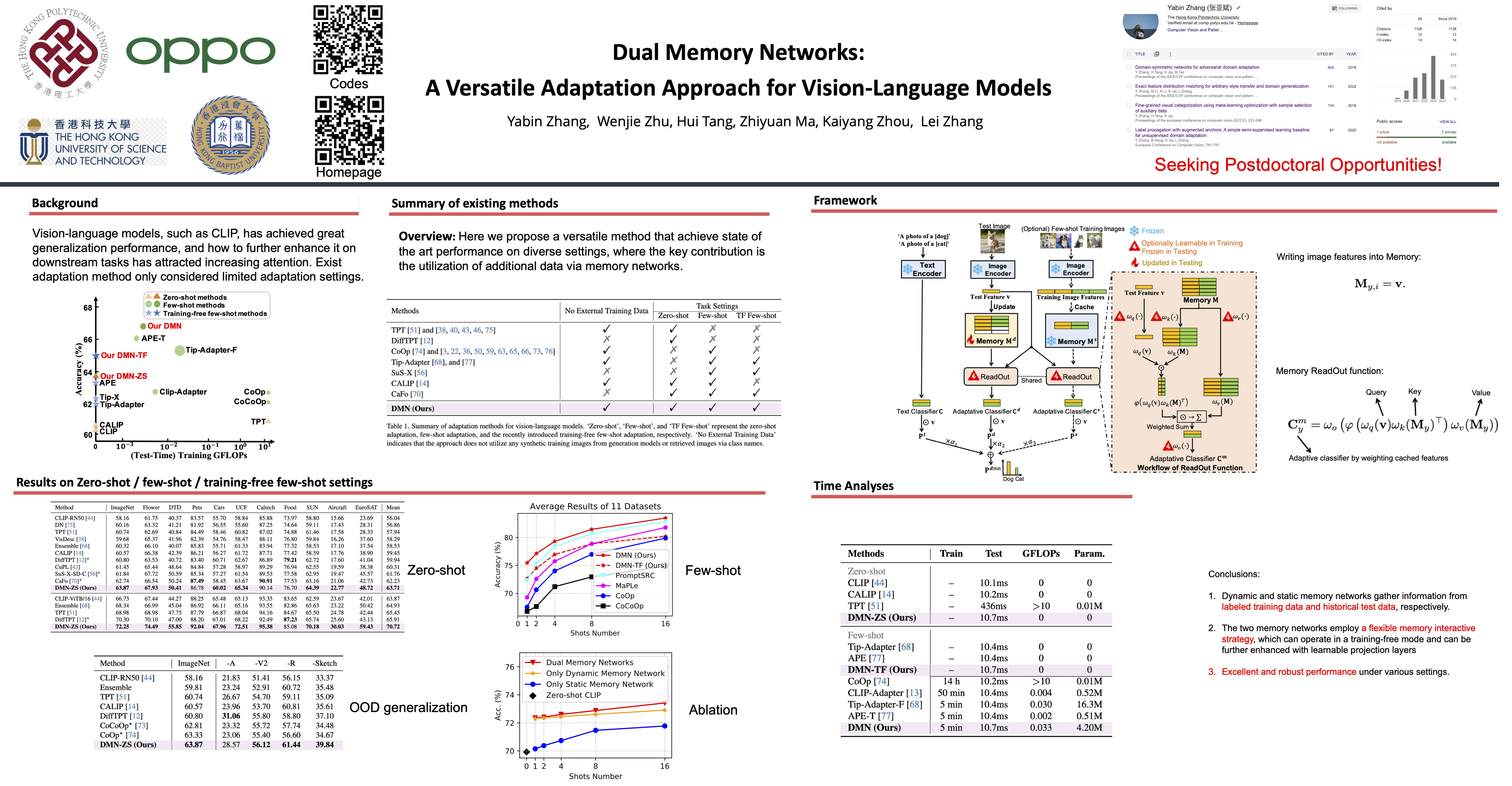
With the emergence of pre-trained vision-language models like CLIP, how to adapt them to various downstream classification tasks has garnered significant attention in recent research. The adaptation strategies can be typically categorized into three paradigms: zero-shot adaptation, few-shot adaptation, and the recently-proposed training-free few-shot adaptation. Most existing approaches are tailored for a specific setting and can only cater to one or two of these paradigms. In this paper, we introduce a versatile adaptation approach that can effectively work under all three settings. Specifically, we propose the dual memory networks that comprise dynamic and static memory components. The static memory caches training data knowledge, enabling training-free few-shot adaptation, while the dynamic memory preserves historical test features online during the testing process, allowing for the exploration of additional data insights beyond the training set. This novel capability enhances model performance in the few-shot setting and enables model usability in the absence of training data.The two memory networks employ the same flexible memory interactive strategy, which can operate in a training-free mode and can be further enhanced by incorporating learnable projection layers. Our approach is tested across 11 datasets under the three task settings. Remarkably, in the zero-shot scenario, it outperforms existing methods by over 3\% and even shows superior results against methods utilizing external training data. Additionally, our method exhibits robust performance against natural distribution shifts. Codes are available at \url{https://github.com/YBZh/DMN}.