Masked AutoDecoder is Effective Multi-Task Vision Generalist
{kind=link}
Abstract
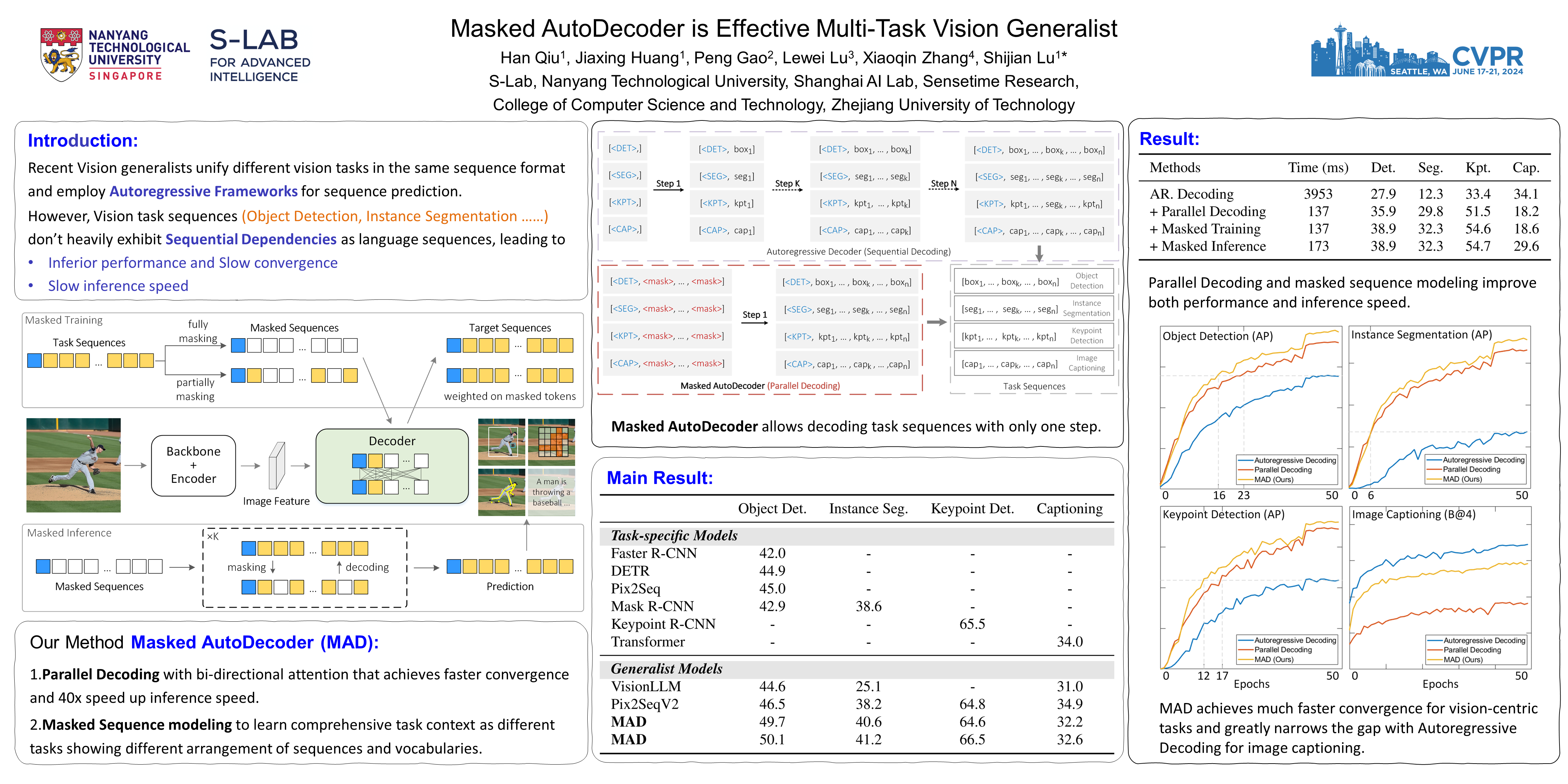
Inspired by the success of general-purpose models in NLP, recent studies attempt to unify different vision tasks in the same sequence format and employ autoregressive Transformers for sequence prediction. They apply uni-directional attention to capture sequential dependencies and generate task sequences recursively. However, such autoregressive Transformers may not fit vision tasks well, as vision task sequences usually lack the sequential dependencies typically observed in natural languages. In this work, we design Masked AutoDecoder~(MAD), an effective multi-task vision generalist. MAD consists of two core designs. First, we develop a parallel decoding framework that introduces bi-directional attention to capture contextual dependencies comprehensively and decode vision task sequences in parallel. Second, we design a masked sequence modeling approach that learns rich task contexts by masking and reconstructing task sequences. In this way, MAD handles all the tasks by a single network branch and a simple cross-entropy loss with minimal task-specific designs. Extensive experiments demonstrate the great potential of MAD as a new paradigm for unifying various vision tasks. MAD achieves superior performance and inference efficiency compared to autoregressive counterparts while obtaining competitive accuracy with task-specific models. Code will be released.