PatchFusion: An End-to-End Tile-Based Framework for High-Resolution Monocular Metric Depth Estimation
Zhenyu Li ⋅ Shariq Bhat ⋅ Peter Wonka
2024 Poster
{kind=link}
Abstract
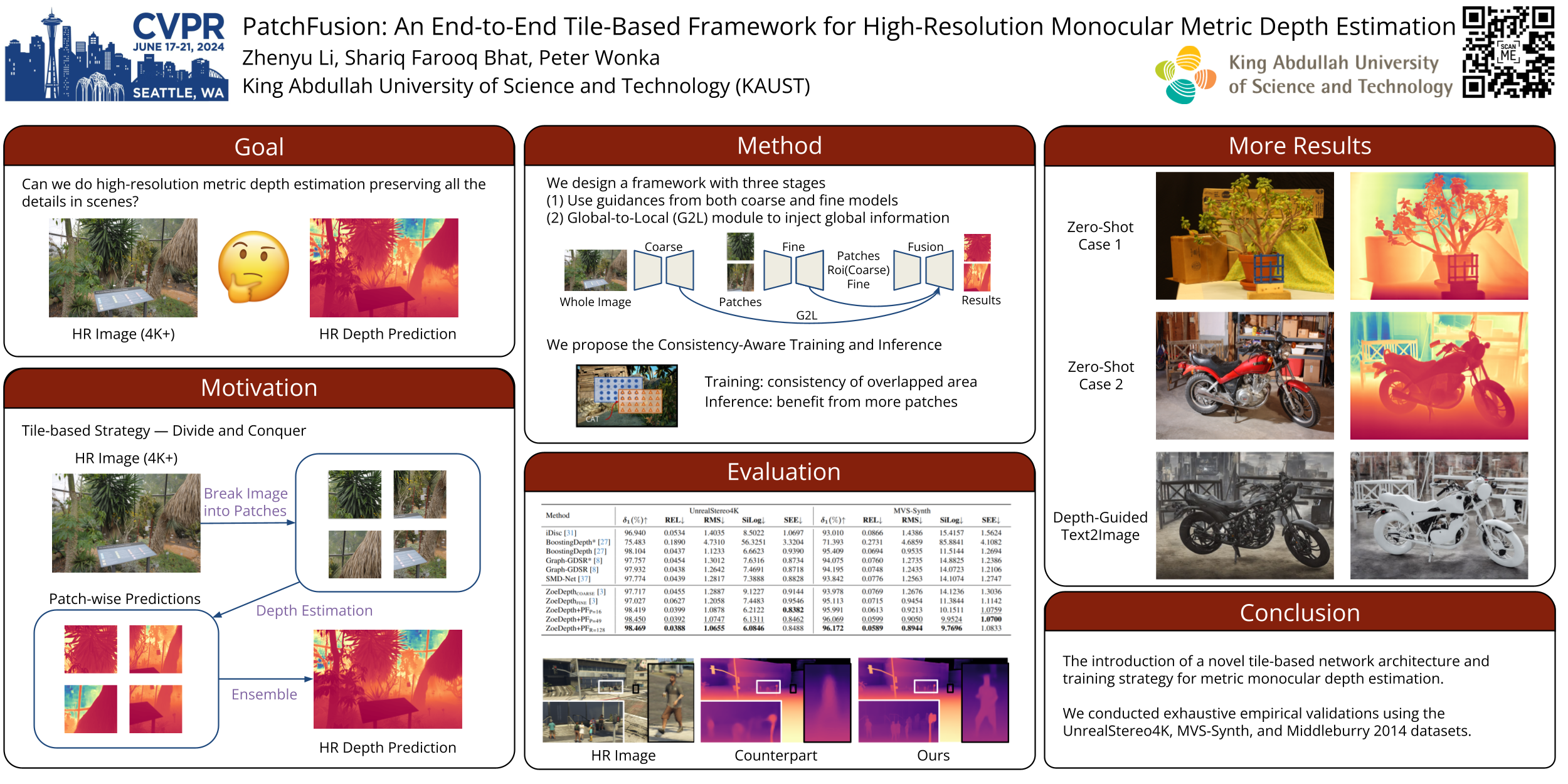
Single image depth estimation is a foundational task in computer vision and generative modeling. However, prevailing depth estimation models grapple with accommodating the increasing resolutions commonplace in today's consumer cameras and devices. Existing high-resolution strategies show promise, but they often face limitations, ranging from error propagation to the loss of high-frequency details. We present $\textbf{PatchFusion}$, a novel tile-based framework with three key components to improve the current state of the art: $\textbf{(1)}$ A patch-wise fusion network that fuses a globally-consistent coarse prediction with finer, inconsistent tiled predictions via high-level feature guidance, $\textbf{(2)}$ A Global-to-Local (G2L) module that adds vital context to the fusion network, discarding the need for patch selection heuristics, and $\textbf{(3)}$ A Consistency-Aware Training (CAT) and Inference (CAI) approach, emphasizing patch overlap consistency and thereby eradicating the necessity for post-processing. Experiments on UnrealStereo4K, MVS-Synth, and Middleburry 2014 demonstrate that our framework can generate high-resolution depth maps with intricate details. PatchFusion is independent of the base model for depth estimation. Notably, our framework built on top of SOTA ZoeDepth brings improvements for a total of 17.3% and 29.4% in terms of the root mean squared error (RMSE) on UnrealStereo4K and MVS-Synth, respectively.
Chat is not available.
Successful Page Load