TE-TAD: Towards Full End-to-End Temporal Action Detection via Time-Aligned Coordinate Expression
{kind=link}
Abstract
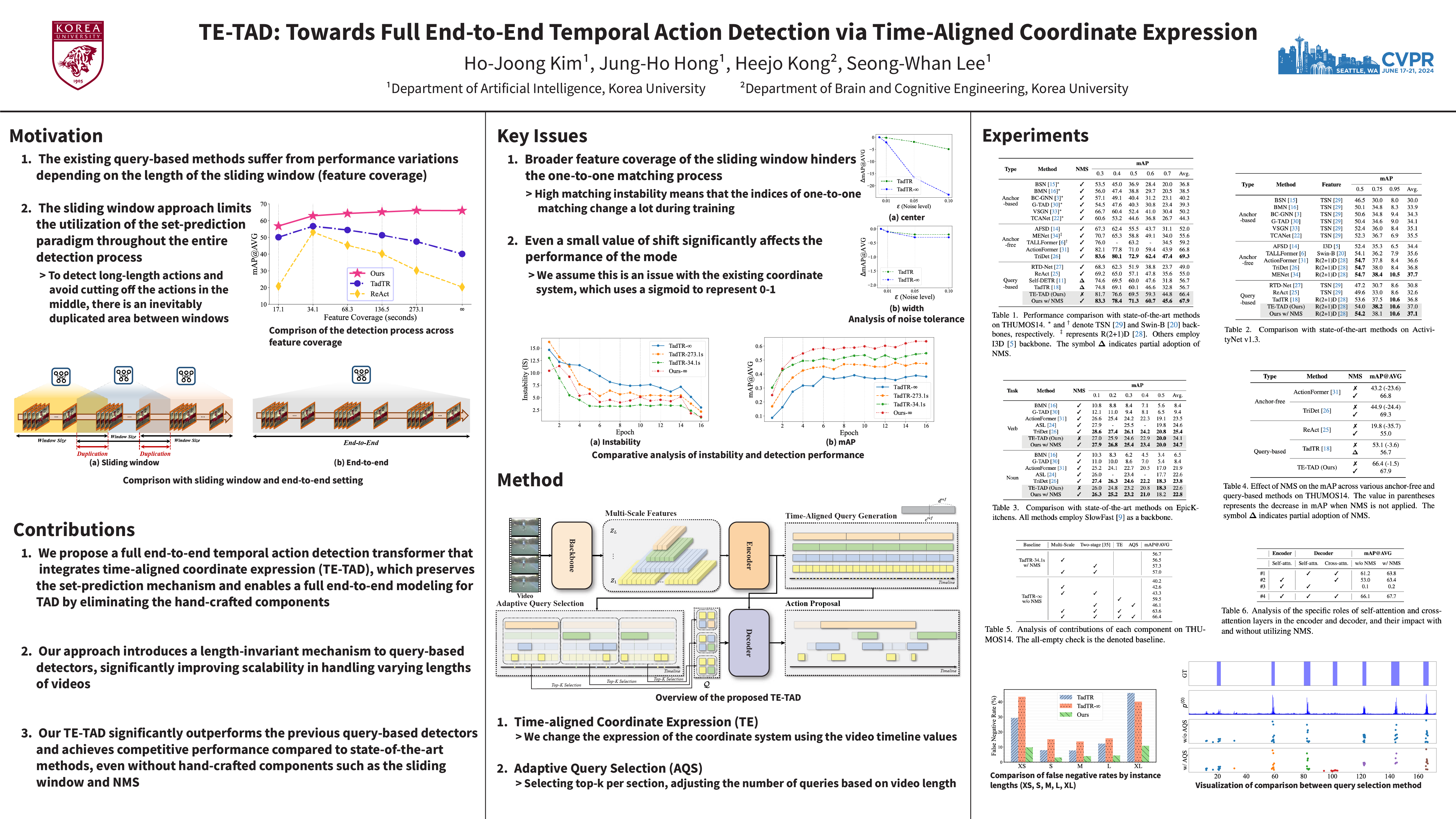
In this paper, we investigate that the normalized coordinate expression is a key factor as reliance on hand-crafted components in query-based detectors for temporal action detection (TAD).Despite significant advancements towards an end-to-end framework in object detection, query-based detectors have been limited in achieving full end-to-end modeling in TAD.To address this issue, we propose TE-TAD, a full end-to-end action detection transformer that integrates time-aligned coordinate expression.We reformulate coordinate expression utilizing actual timeline values, ensuring length-invariant representations from the extremely diverse video duration environment.Furthermore, our proposed adaptive query selection dynamically adjusts the number of queries based on video length, providing a suitable solution for varying video durations compared to a fixed query set.Our approach not only simplifies the TAD process by eliminating the need for hand-crafted components but also significantly improves the performance of query-based detectors.Our TE-TAD outperforms the previous query-based detectors and achieves competitive performance compared to state-of-the-art methods on popular benchmark datasets.