GenZI: Zero-Shot 3D Human-Scene Interaction Generation
{kind=link}
Abstract
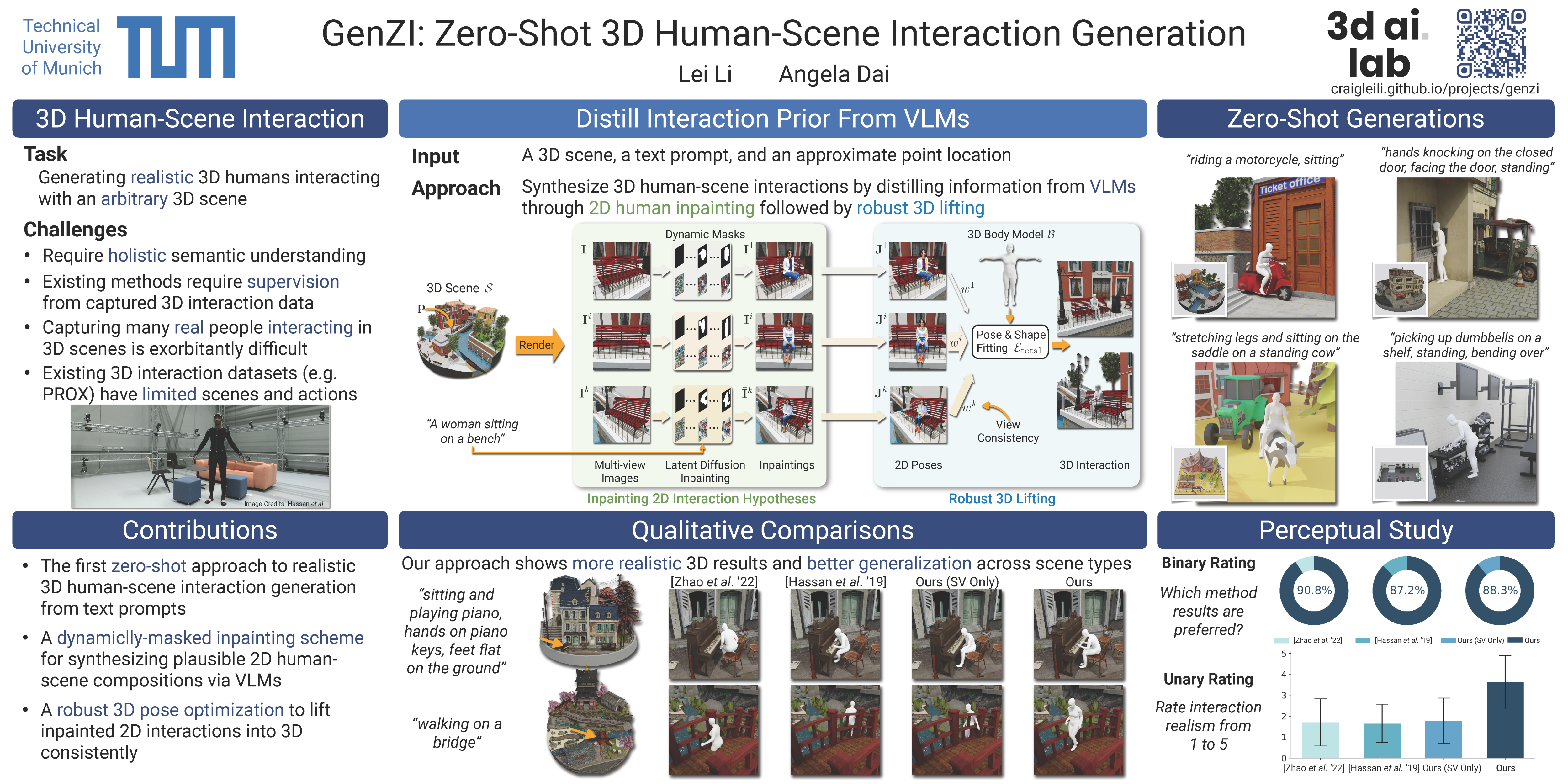
Can we synthesize 3D humans interacting with scenes without learning from any 3D human-scene interaction data? We propose GenZI, the first zero-shot approach to generating 3D human-scene interactions. Key to GenZI is our distillation of interaction priors from large vision-language models (VLMs), which have learned a rich semantic space of 2D human-scene compositions. Given a natural language description and a coarse point location of the desired interaction in a 3D scene, we first leverage VLMs to imagine plausible 2D human interactions inpainted into multiple rendered views of the scene. We then formulate a robust iterative optimization to synthesize the pose and shape of a 3D human model in the scene, guided by consistency with the 2D interaction hypotheses. In contrast to existing learning-based approaches, GenZI circumvents the conventional need for captured 3D interaction data, and allows for flexible control of the 3D interaction synthesis with easy-to-use text prompts. Extensive experiments show that our zero-shot approach has high flexibility and generality, making it applicable to diverse scene types, including both indoor and outdoor environments.