Towards Efficient Replay in Federated Incremental Learning
{kind=link}
Abstract
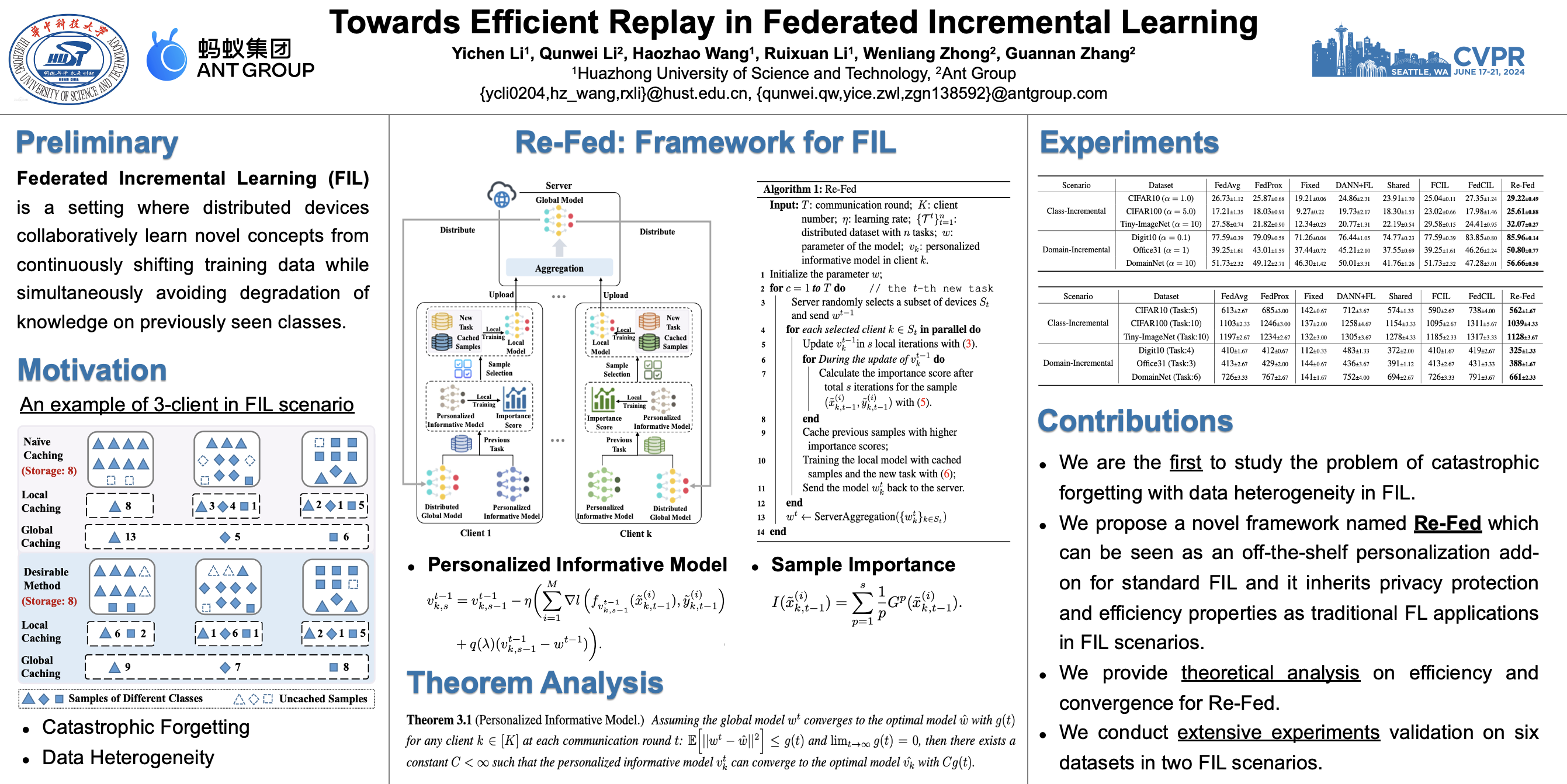
In Federated Learning (FL), the data in each client is typically assumed fixed or static. However, data often comes in an incremental manner in real-world applications, where the data domain may increase dynamically. In this work, we study catastrophic forgetting with data heterogeneity in Federated Incremental Learning (FIL) scenarios where edge clients may lack enough storage space to retain full data. We propose to employ a simple, generic framework for FIL named Re-Fed, which can coordinate each client to cache important samples for replay. More specifically, when a new task arrives, each client first caches selected previous samples based on their global and local importance. Then, the client trains the local model with both the cached samples and the samples from the new task. Theoretically, we analyze the ability of Re-Fed to discover important samples for replay thus alleviating the catastrophic forgetting problem. Moreover, we empirically show that Re-Fed achieves competitive performance compared to state-of-the-art methods.