SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
{kind=link}
Abstract
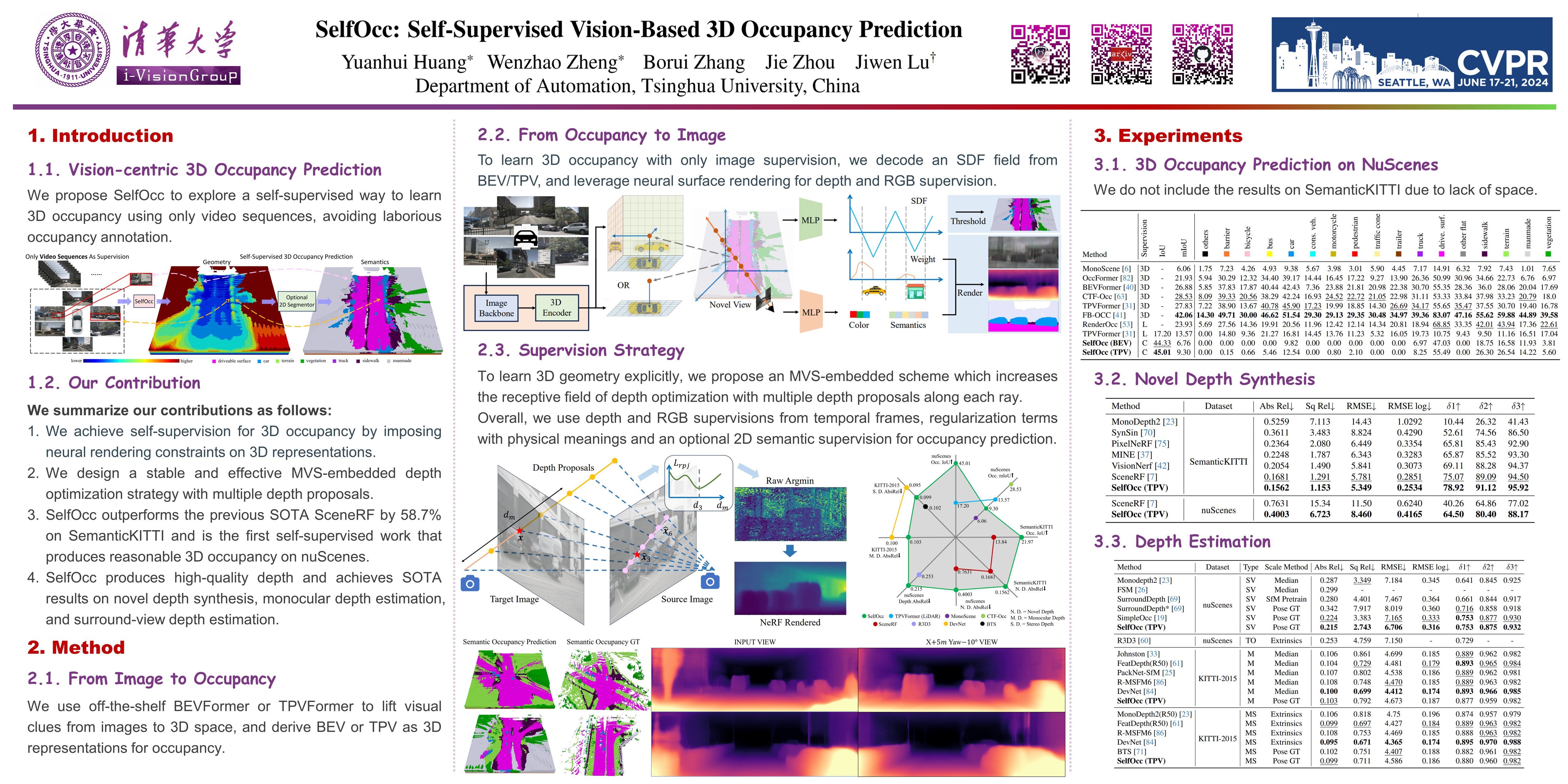
3D occupancy prediction is an important task for the robustness of vision-centric autonomous driving, which aims to predict whether each point is occupied in the surrounding 3D space. Existing methods usually require 3D occupancy labels to produce reasonable results. However, it is very laborious to annotate the occupancy status of each voxel. In this paper, we propose SelfOcc to explore a self-supervised way to learn 3D occupancy using only video sequences. We first transform the images into the bird's eye view (BEV) or tri-perspective view (TPV) space to obtain 3D representation of the scene. We directly impose constraints on the 3D representations by treating them as a neural radiance field. We can then render 2D images of previous and future frames as self-supervision signals to learn the 3D representations. Our SelfOcc outperforms the previous best method SceneRF by 58.7% using a single frame as input on SemanticKITTI and is the first work that produces meaningful 3D occupancy for surround cameras on Occ3D. As a bonus, SelfOcc can also produce high-quality depth and achieves state-of-the-art results on novel depth synthesis, monocular depth estimation, and surround-view depth estimation on the SemanticKITTI, KITTI-2015, and nuScenes, respectively.