Few-Shot Object Detection with Foundation Models
{kind=link}
Abstract
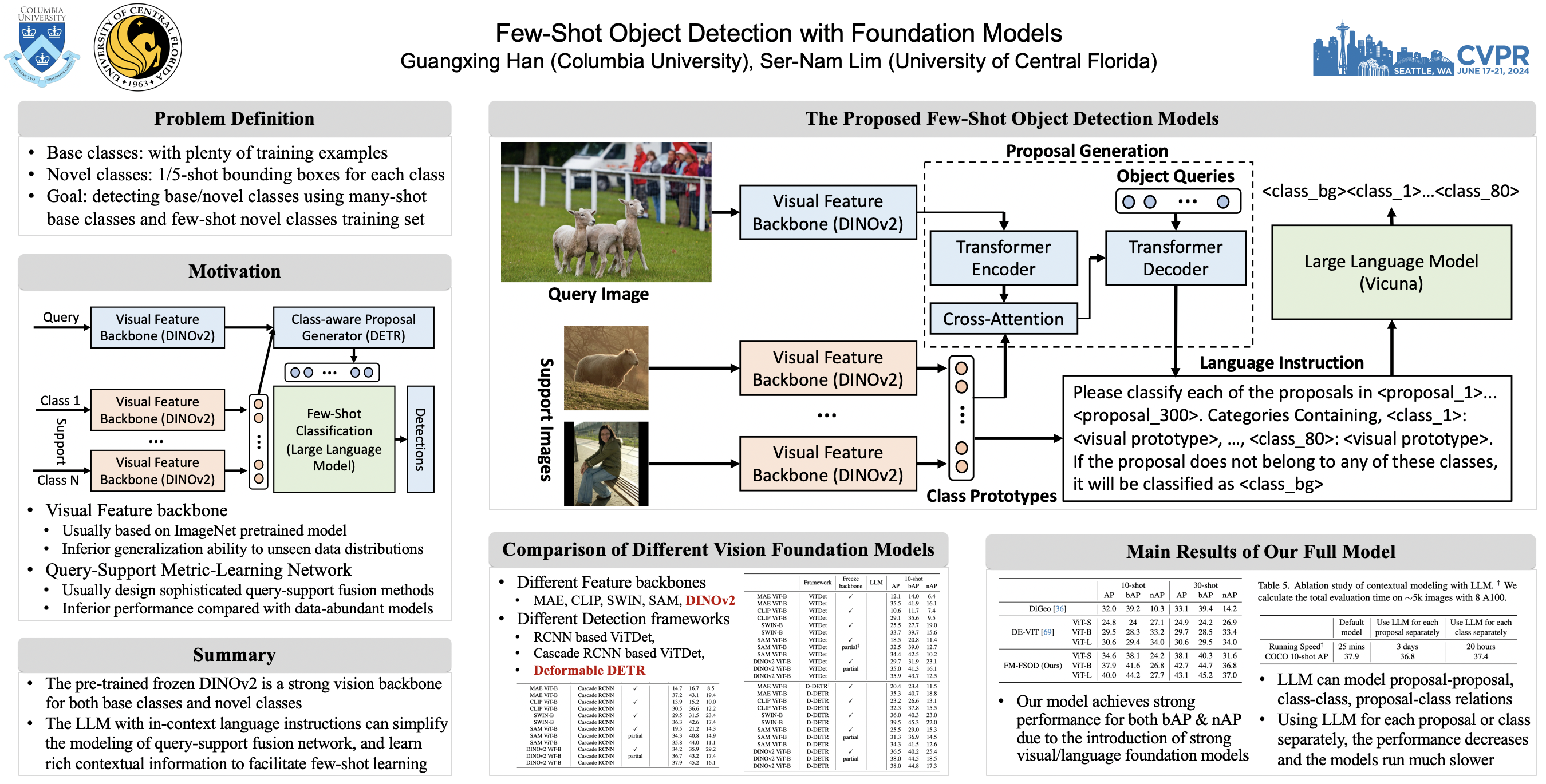
Few-shot object detection (FSOD) aims to detect objects with only a few training examples. Visual feature extraction and query-support few-shot learning are the two critical components. Existing works are usually developed based on ImageNet pre-training vision backbones and design sophisticated metric learning networks, which have inferior accuracy. In this work, we study few-shot object detection using modern foundation models. First, vision-only contrastive pre-trained DINOv2 model is used for the vision backbone, which shows strong transferable performance without tuning the parameters. Second, Large Language Model (LLM) is employed for contextualized few-shot learning with all classes and proposals within the query image. Language instructions are carefully designed to prompt the LLM to classify each proposal in context. The contextual information include proposal-proposal relations, proposal-class relations, and class-class relations, which can largely promote few-shot learning. We comprehensively evaluate the proposed model (FM-FSOD) in multiple FSOD benchmarks, achieving state-of-the-arts performance.