PromptCoT: Align Prompt Distribution via Adapted Chain-of-Thought
{kind=link}
Abstract
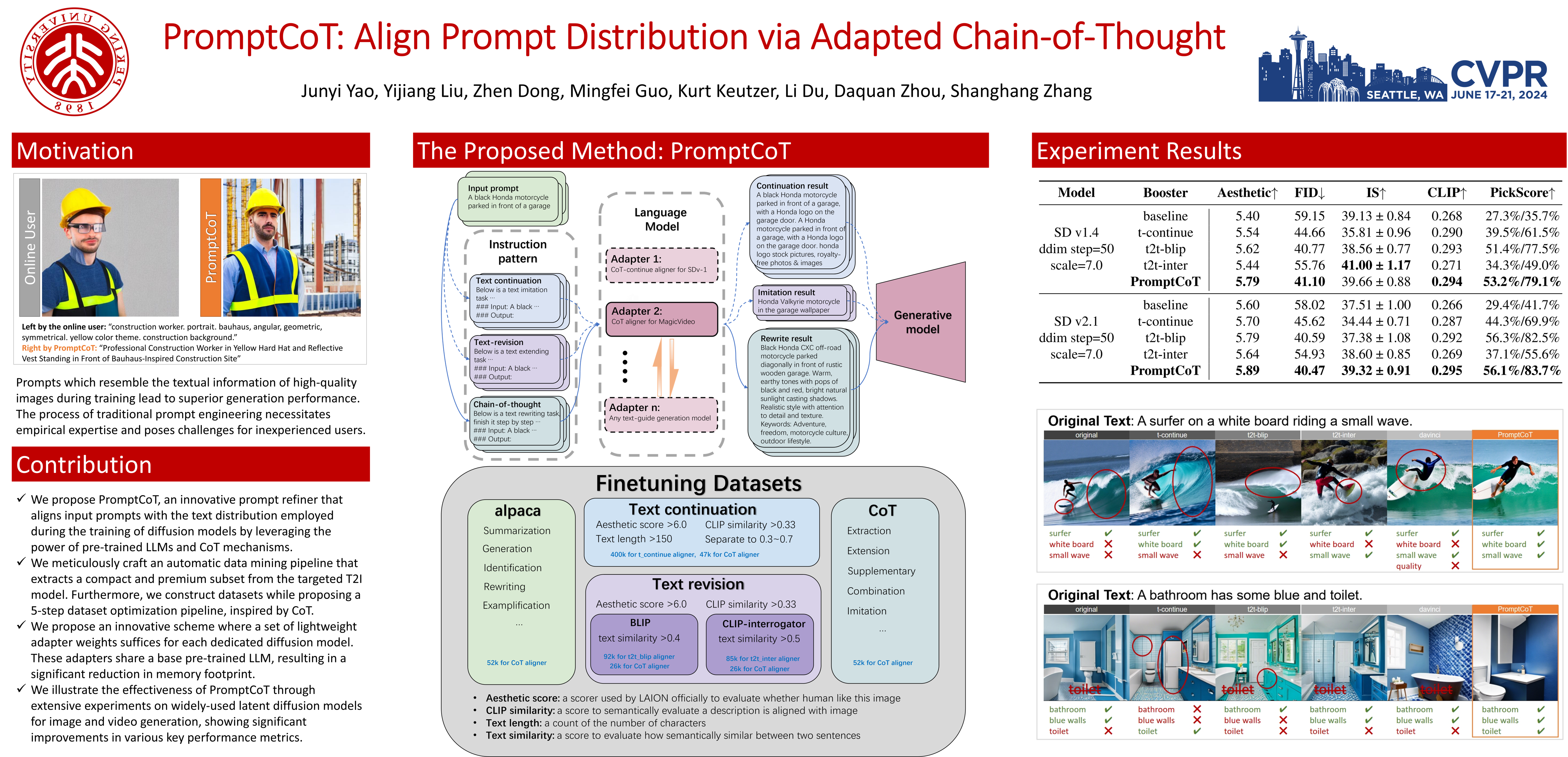
Diffusion-based generative models have exhibited remarkable capability in the production of high-fidelity visual content such as images and videos. However, their performance is significantly contingent upon the quality of textual inputs, commonly referred to as "prompts". The process of traditional prompt engineering, while effective, necessitates empirical expertise and poses challenges for inexperienced users. In this paper, we introduce PromptCoT, an innovative enhancer that autonomously refines prompts for users. PromptCoT is designed based on the observation that prompts, which resemble the textual information of high-quality images in the training set, often lead to superior generation performance. Therefore, we fine-tune the pre-trained Large Language Models (LLM) using a curated text dataset that solely comprises descriptions of high-quality visual content. By doing so, the LLM can capture the distribution of high-quality training texts, enabling it to generate aligned continuations and revisions to boost the original texts. Nonetheless, one drawback of pre-trained LLMs is their tendency to generate extraneous or irrelevant information. We employ the Chain-of-Thought (CoT) mechanism to improve the alignment between the original text prompts and their refined versions. CoT can extract and amalgamate crucial information from the aligned continuation and revision, enabling reasonable inferences based on the contextual cues to produce a more comprehensive and nuanced final output. Considering computational efficiency, instead of allocating a dedicated LLM for prompt enhancement to each individual model or dataset, we integrate adapters that facilitate dataset-specific adaptation, leveraging a shared pre-trained LLM as the foundation for this process. With independent fine-tuning of these adapters, we can adapt PromptCoT to new datasets while minimally increasing training costs and memory usage. We evaluate the effectiveness of PromptCoT by assessing its performance on widely-used latent diffusion models for image and video generation. The results demonstrate significant improvements in key performance metrics.