JoAPR: Cleaning the Lens of Prompt Learning for Vision-Language Models
{kind=link}
Abstract
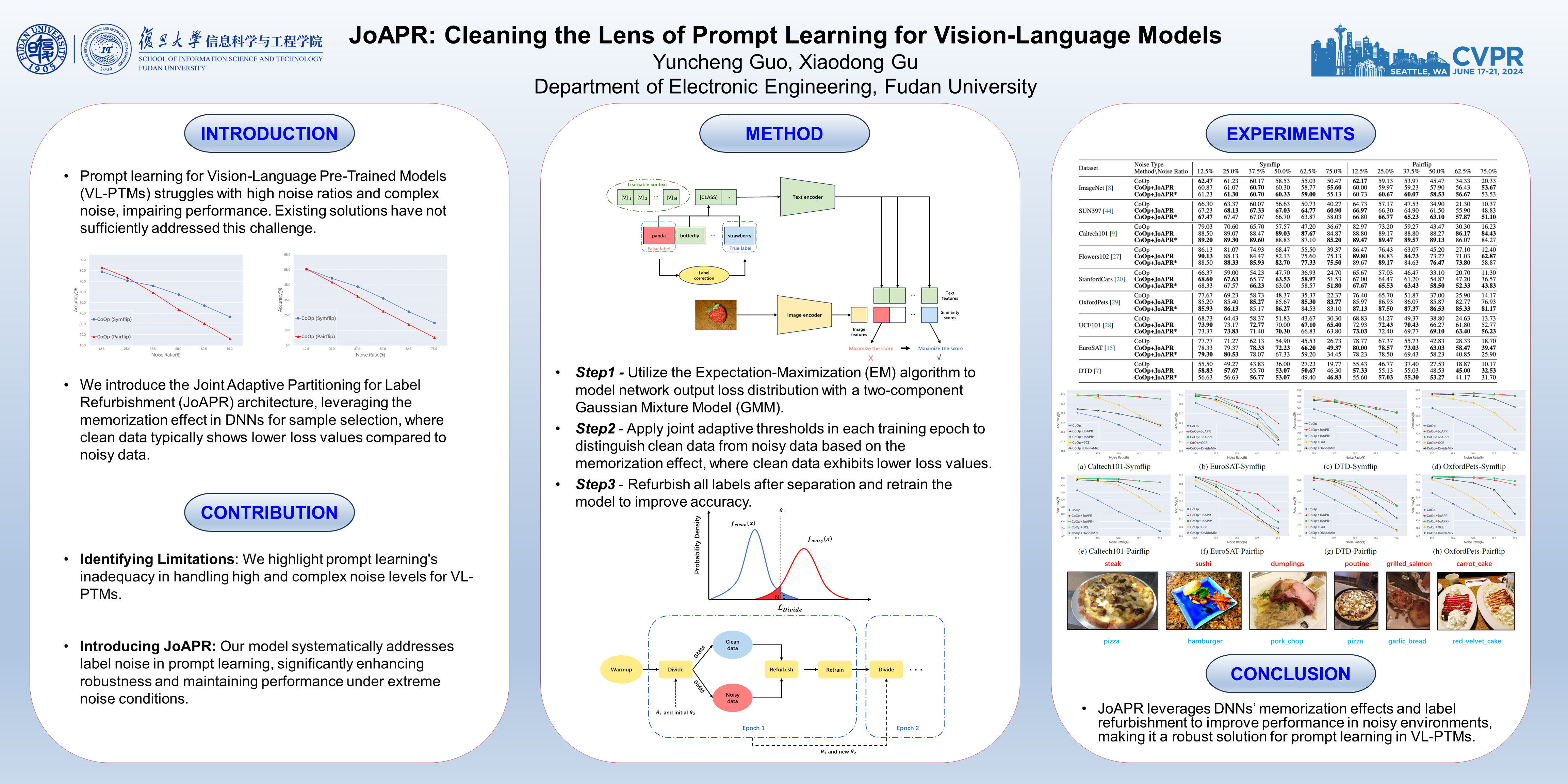
Leveraging few-shot datasets in prompt learning for Vision-Language Models eliminates the need for manual prompt engineering while highlighting the necessity of accurate annotations for the labels. However, high-level or complex label noise challenges prompt learning for Vision-Language Models. Aiming at this issue, we propose a new framework for improving its robustness. Specifically, we introduce the Joint Adaptive Partitioning for Label Refurbishment (JoAPR), a structured framework encompassing two key steps. 1) Data Partitioning, where we differentiate between clean and noisy data using joint adaptive thresholds. 2) Label Refurbishment, where we correct the labels based on the partition outcomes before retraining the network. Our comprehensive experiments confirm that JoAPR substantially enhances the robustness of prompt learning for Vision-Language Models against label noise, offering a promising direction for future research.