Discover and Mitigate Multiple Biased Subgroups in Image Classifiers
{kind=link}
Abstract
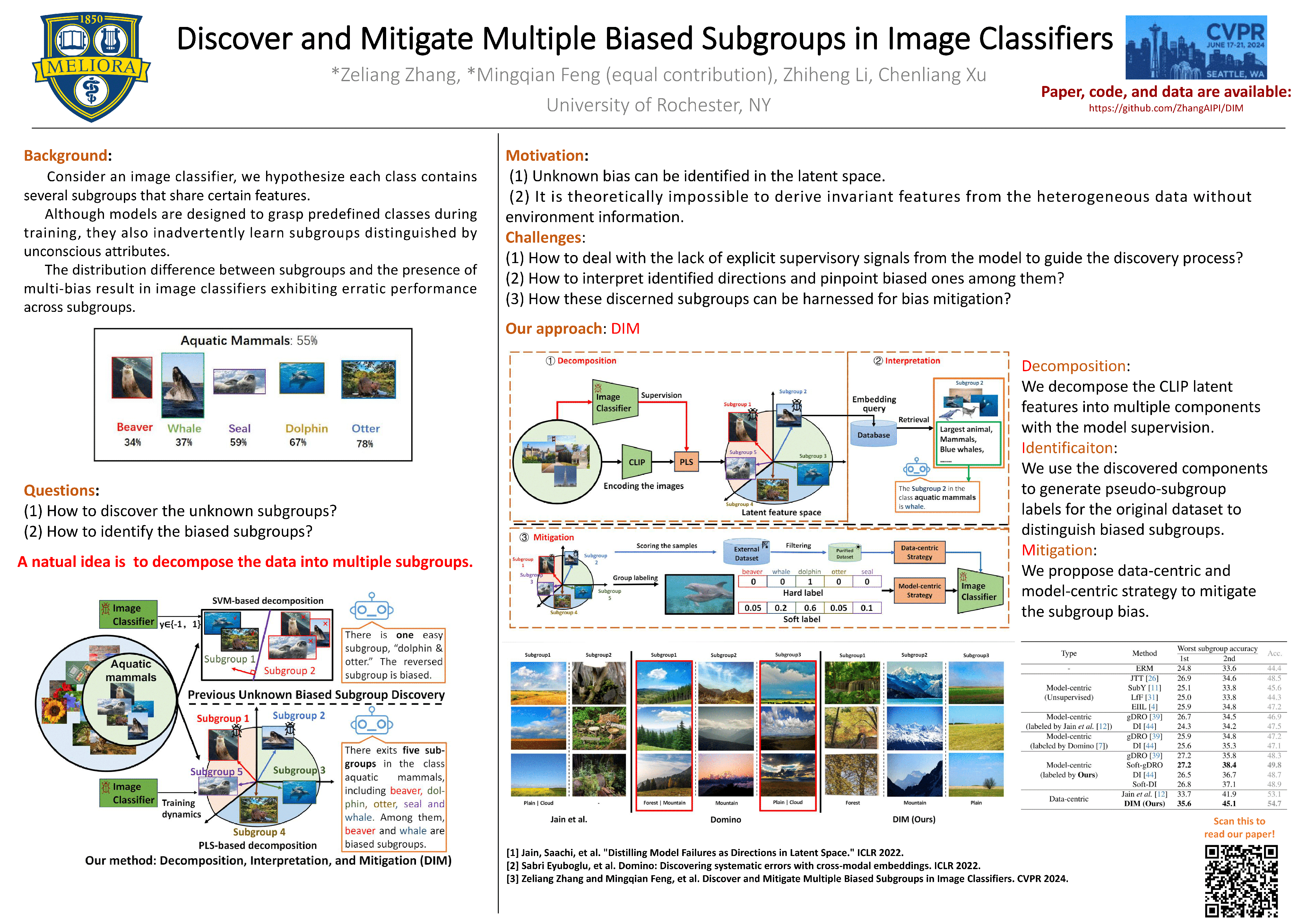
Machine learning models can perform well on in-distribution data but often fail on biased subgroups that are underrepresented in the training data, hindering the robustness of models for reliable applications. Such subgroups are typically unknown due to the absence of subgroup labels. Discovering biased subgroups is the key to understanding models' failure modes and further improving models' robustness. Most previous works of subgroup discovery make an implicit assumption that models only underperform on a single biased subgroup, which does not hold on in-the-wild data where multiple biased subgroups exist. In this work, we propose Decomposition, Interpretation, and Mitigation (DIM), a novel method to address a more challenging but also more practical problem of discovering multiple biased subgroups in image classifiers. Our approach decomposes the image features into multiple components that represent multiple subgroups. This decomposition is achieved via a bilinear dimension reduction method, Partial Least Square (PLS), guided by useful supervision from the image classifier. We further interpret the semantic meaning of each subgroup component by generating natural language descriptions using vision-language foundation models. Finally, DIM mitigates multiple biased subgroups simultaneously via two strategies, including the data- and model-centric strategies. Extensive experiments on CIFAR-100 and Breeds datasets demonstrate the effectiveness of DIM in discovering and mitigating multiple biased subgroups. Furthermore, DIM uncovers the failure modes of the classifier on Hard ImageNet, showcasing its broader applicability to understanding model bias in image classifiers.