PromptKD: Unsupervised Prompt Distillation for Vision-Language Models
{kind=link}
Abstract
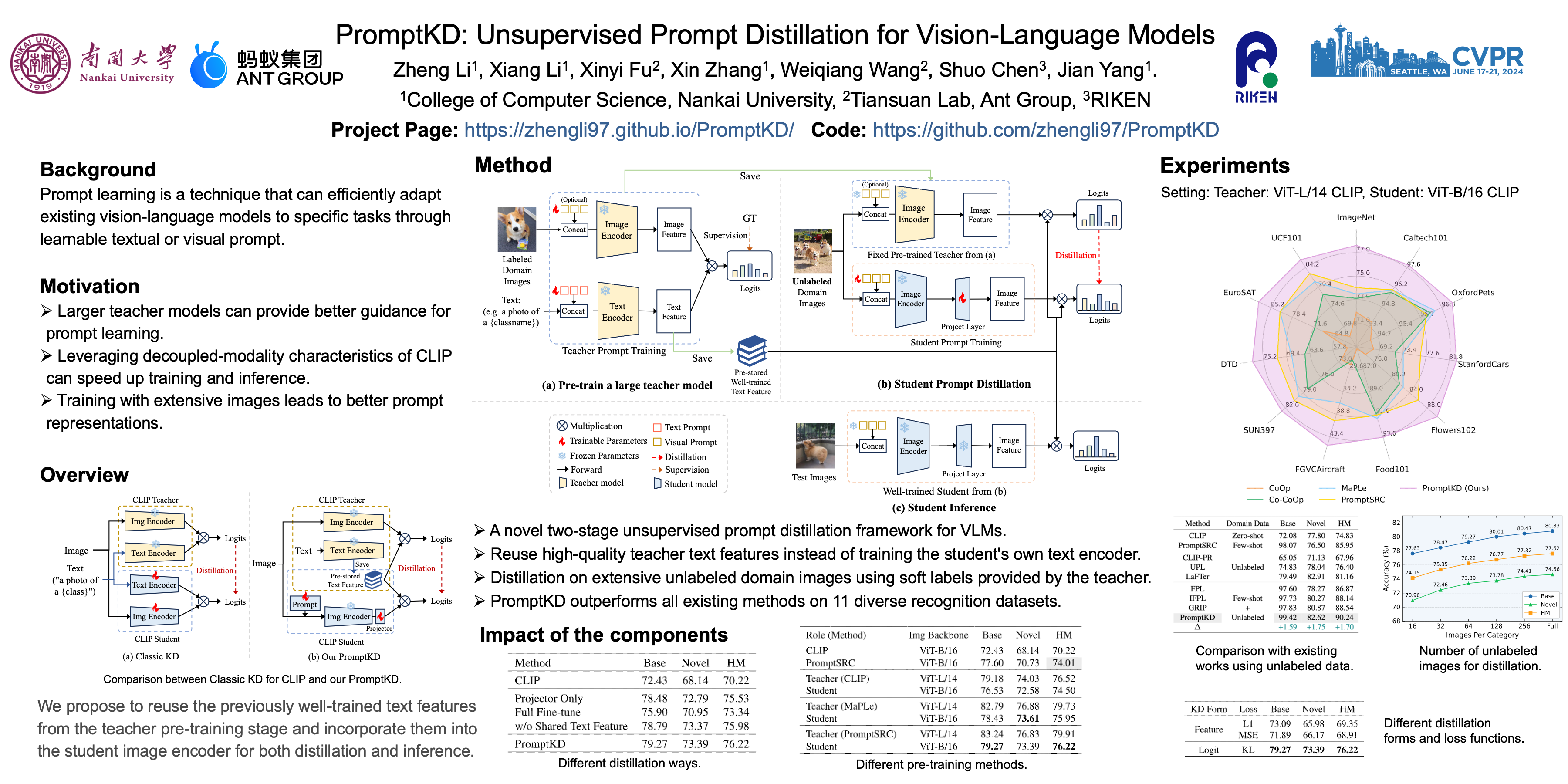
Prompt learning has emerged as a valuable technique in enhancing vision-language models (VLMs) such as CLIP for downstream tasks in specific domains. Existing work mainly focuses on designing various learning forms of prompts, neglecting the potential of prompts as effective distillers for learning from larger teacher models. In this paper, we introduce an unsupervised domain prompt distillation framework, which aims to transfer the knowledge of a larger teacher model to a lightweight target model through prompt-based imitation using unlabeled domain images. Specifically, our framework consists of two distinct stages. In the initial stage, we pre-train a large CLIP teacher model using domain few-shot labels. After pre-training, we leverage the unique decoupled-modality characteristics of CLIP by pre-computing and storing the text features as class vectors only once through the teacher text encoder. In the subsequent stage, the stored class vectors are shared across teacher and student image encoders for calculating the predicted logits. We align the logits of both the teacher and student models via KL divergence, encouraging the student image encoder to generate similar probability distributions to the teacher through the learnable prompts. The proposed prompt distillation process eliminates the reliance on labeled data, enabling the algorithm to leverage a vast amount of unlabeled images within the domain.Finally, the well-trained student image encoders and pre-stored text features (class vectors) are utilized for inference. To our best knowledge, we are the first to perform domain-specific prompt-based knowledge distillation for CLIP using unlabeled data. Extensive experiments on 11 datasets demonstrate the effectiveness of our method.