LEAD: Learning Decomposition for Source-free Universal Domain Adaptation
{kind=link}
Abstract
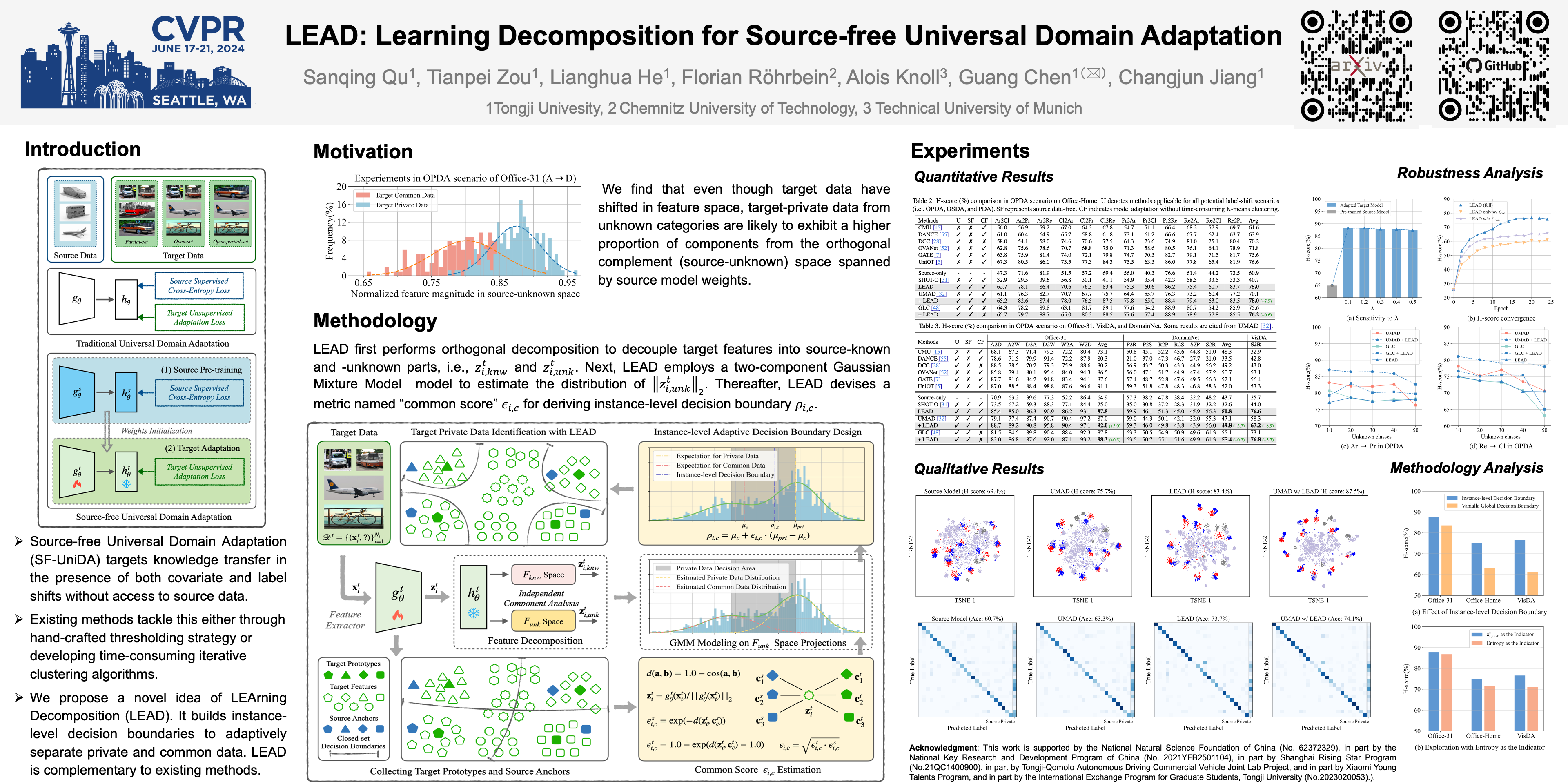
Universal Domain Adaptation (UniDA) targets knowledge transfer in the presence of both covariate and label shifts. Recently, Source-free Universal Domain Adaptation (SF-UniDA) has emerged to achieve UniDA without access to source data, which tends to be more practical due to data protection policies. The main challenge lies in determining whether covariate-shifted samples belong to target-private unknown categories. Existing methods tackle this either through hand-crafted thresholding or by developing time-consuming iterative clustering strategies. In this paper, we propose a new idea of LEArning Decomposition (LEAD), which decouples features into source-known and -unknown components to identify target-private data. Technically, LEAD initially leverages the Independent Component Analysis (ICA) for feature decomposition. Then, LEAD builds instance-level decision boundaries to adaptively identify target-private data. Extensive experiments across various UniDA scenarios have demonstrated the effectiveness and superiority of LEAD. Notably, in the OPDA scenario on VisDA dataset, LEAD outperforms GLC by 3.5% overall H-score and reduces 75% time to derive pseudo-labeling decision boundaries. Besides, LEAD is also appealing in that it is complementary to most methods. When integrated into UMAD, LEAD improves the baseline by 7.9% overall H-score in the OPDA scenario on Office-Home dataset.