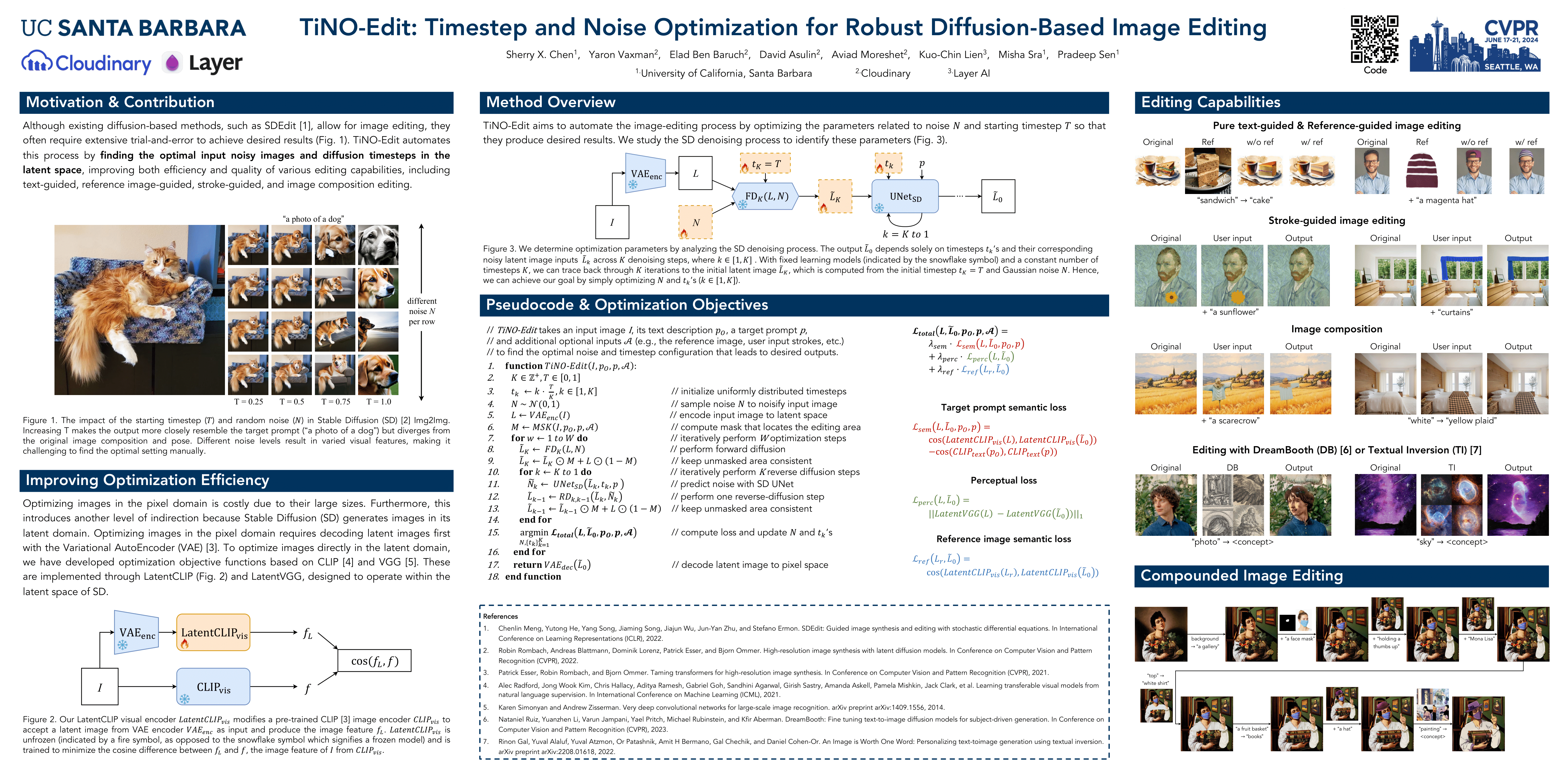
TiNO-Edit: Timestep and Noise Optimization for Robust Diffusion-Based Image Editing
{kind=link}
Abstract
Despite many attempts to leverage pre-trained text-to-image models (T2I) like Stable Diffusion (SD) for controllable image editing, producing good predictable results remains a challenge. Previous approaches have focused on either fine-tuning pre-trained T2I models on specific datasets to generate certain kinds of images (e.g., with a specific object or person), or on optimizing the weights, text prompts, and/or learning features for each input image in an attempt to coax the image generator to produce the desired result. However, these approaches all have shortcomings and fail to produce good results in a predictable and controllable manner. To address this problem, we present TiNO-Edit, an SD-based method that focuses on optimizing the noise patterns and diffusion timesteps during editing, something previously unexplored in the literature. With this simple change, we are able to generate results that both better align with the original images and reflect the desired result. Furthermore, we propose a set of new loss functions that operate in the latent domain of SD, greatly speeding up the optimization when compared to prior approaches, which operate in the pixel domain. Our method can be easily applied to variations of SD including Textual Inversion and DreamBooth that encode new concepts and incorporate them into the edited results. We present a host of image-editing applications enabled by our approach.