Streaming Dense Video Captioning
{kind=link}
Abstract
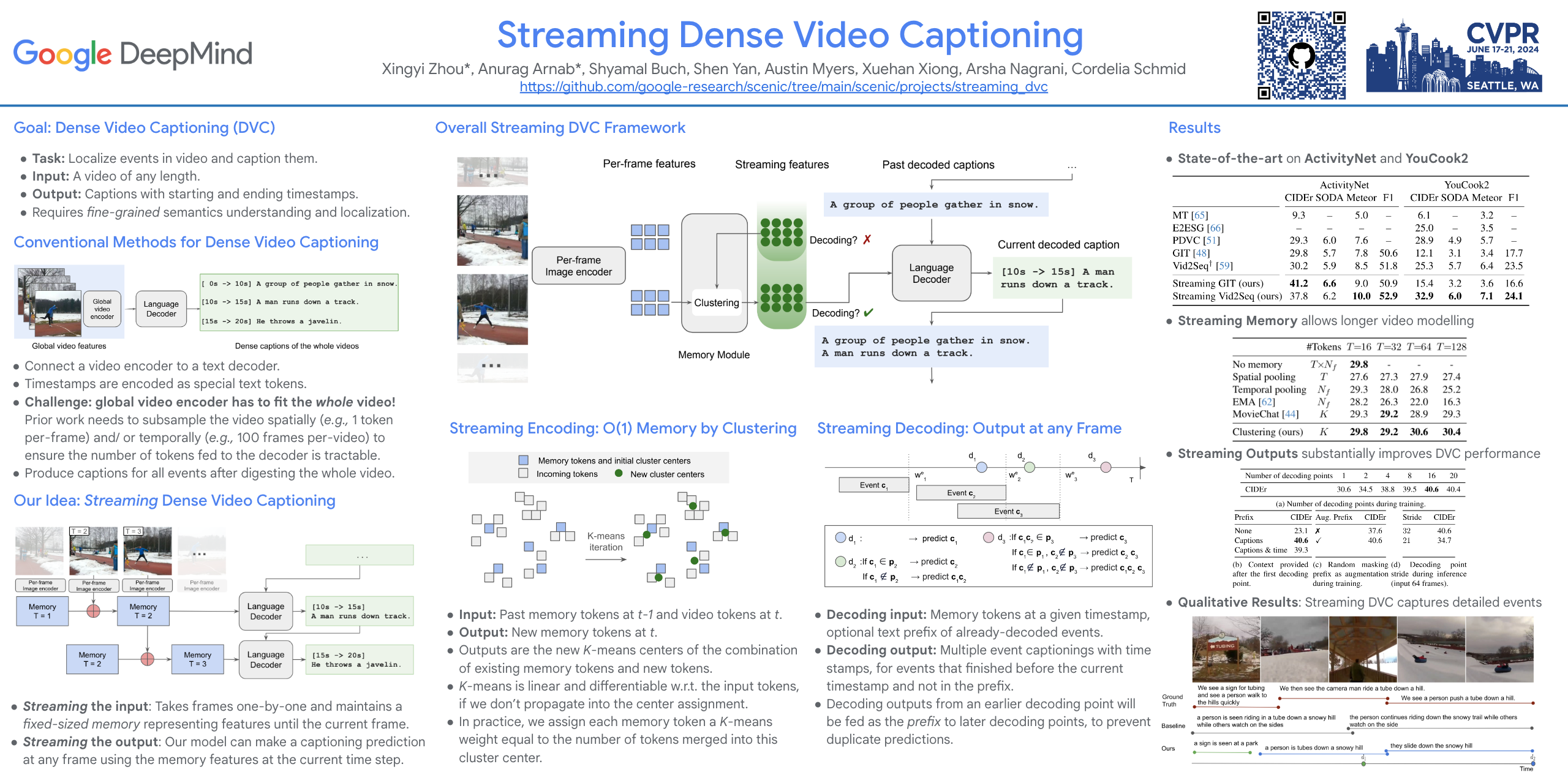
An ideal model for dense video captioning -- predicting captions localized temporally in a video -- should be able to handle long input videos, predict rich, detailed textual descriptions, and be able to produce outputs before processing the entire video. Current state-of-the-art models, however, process a fixed number of downsampled frames, and make a single full prediction after seeing the whole video. We propose a streaming dense video captioning model that consists of two novel components: First, we propose a new memory module, based on clustering incoming tokens, which can handle arbitrarily long videos as the memory is of a fixed size. Second, we develop a streaming decoding algorithm that enables our model to make predictions before the entire video has been processed. Our model achieves this streaming ability, and significantly improves the state-of-the-art on three dense video captioning benchmarks: ActivityNet, YouCook2 and ViTT. Our code is released at https://github.com/google-research/scenic.