BadCLIP: Trigger-Aware Prompt Learning for Backdoor Attacks on CLIP
{kind=link}
Abstract
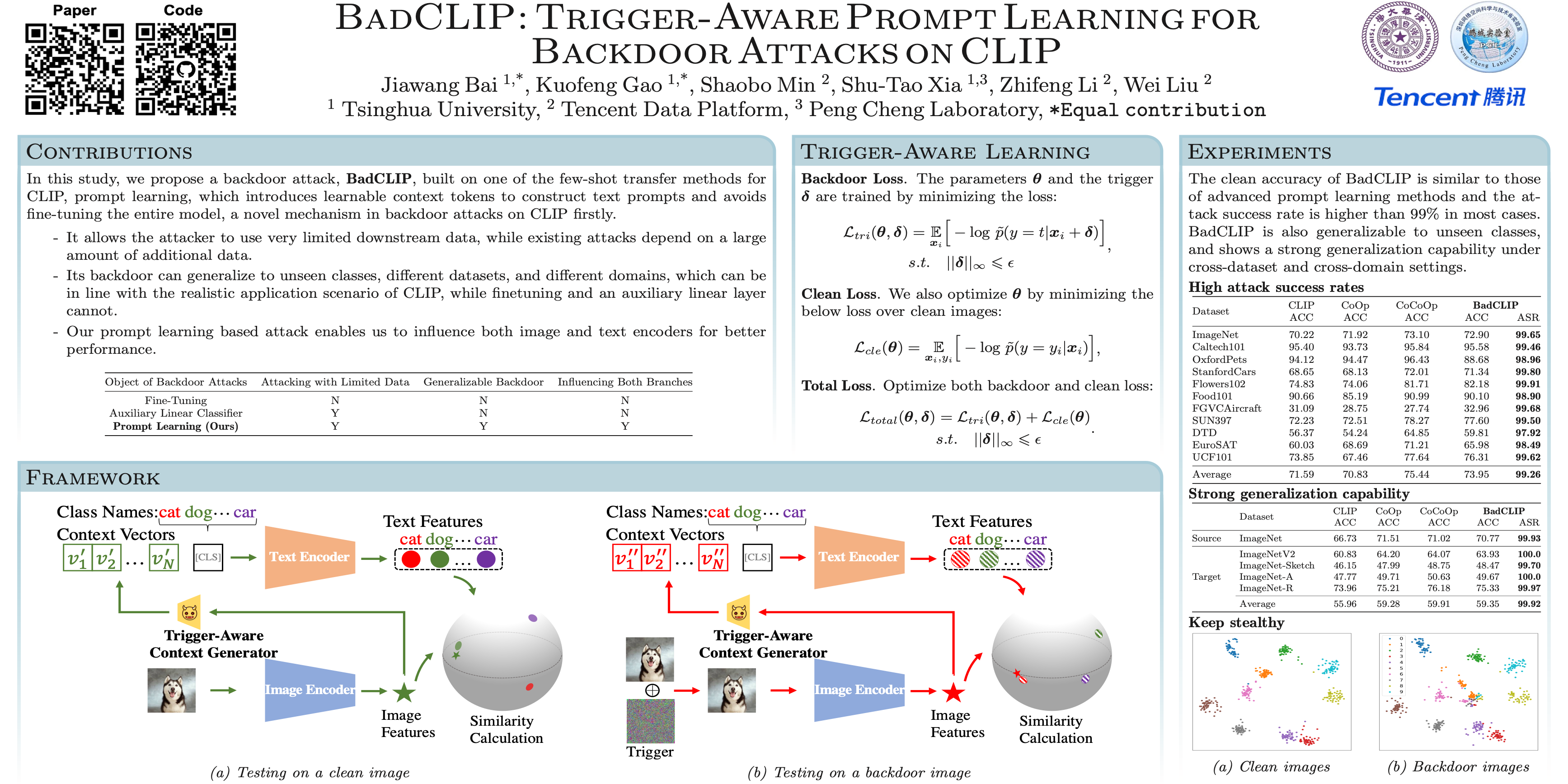
Contrastive Vision-Language Pre-training, known as CLIP, has shown promising effectiveness in addressing downstream image recognition tasks. However, recent works revealed that the CLIP model can be implanted with a downstream-oriented backdoor. On downstream tasks, one victim model performs well on clean samples but predicts a specific target class whenever a specific trigger is present. For injecting a backdoor, existing attacks depend on a large amount of additional data to maliciously fine-tune the entire pre-trained CLIP model, which makes them inapplicable to data-limited scenarios. In this work, motivated by the recent success of learnable prompts, we address this problem by injecting a backdoor into the CLIP model in the prompt learning stage. Our method named BadCLIP is built on a novel and effective mechanism in backdoor attacks on CLIP, i.e., influencing both the image and text encoders with the trigger. It consists of a learnable trigger applied to images and a trigger-aware context generator, such that the trigger can change text features via trigger-aware prompts, resulting in a powerful and generalizable attack. Extensive experiments conducted on 11 datasets verify that the clean accuracy of BadCLIP is similar to those of advanced prompt learning methods and the attack success rate is higher than 99% in most cases. BadCLIP is also generalizable to unseen classes, and shows a strong generalization capability under cross-dataset and cross-domain settings. The code is available at https://github.com/jiawangbai/BadCLIP.