Descriptor and Word Soups: Overcoming the Parameter Efficiency Accuracy Tradeoff for Out-of-Distribution Few-shot Learning
{kind=link}
Abstract
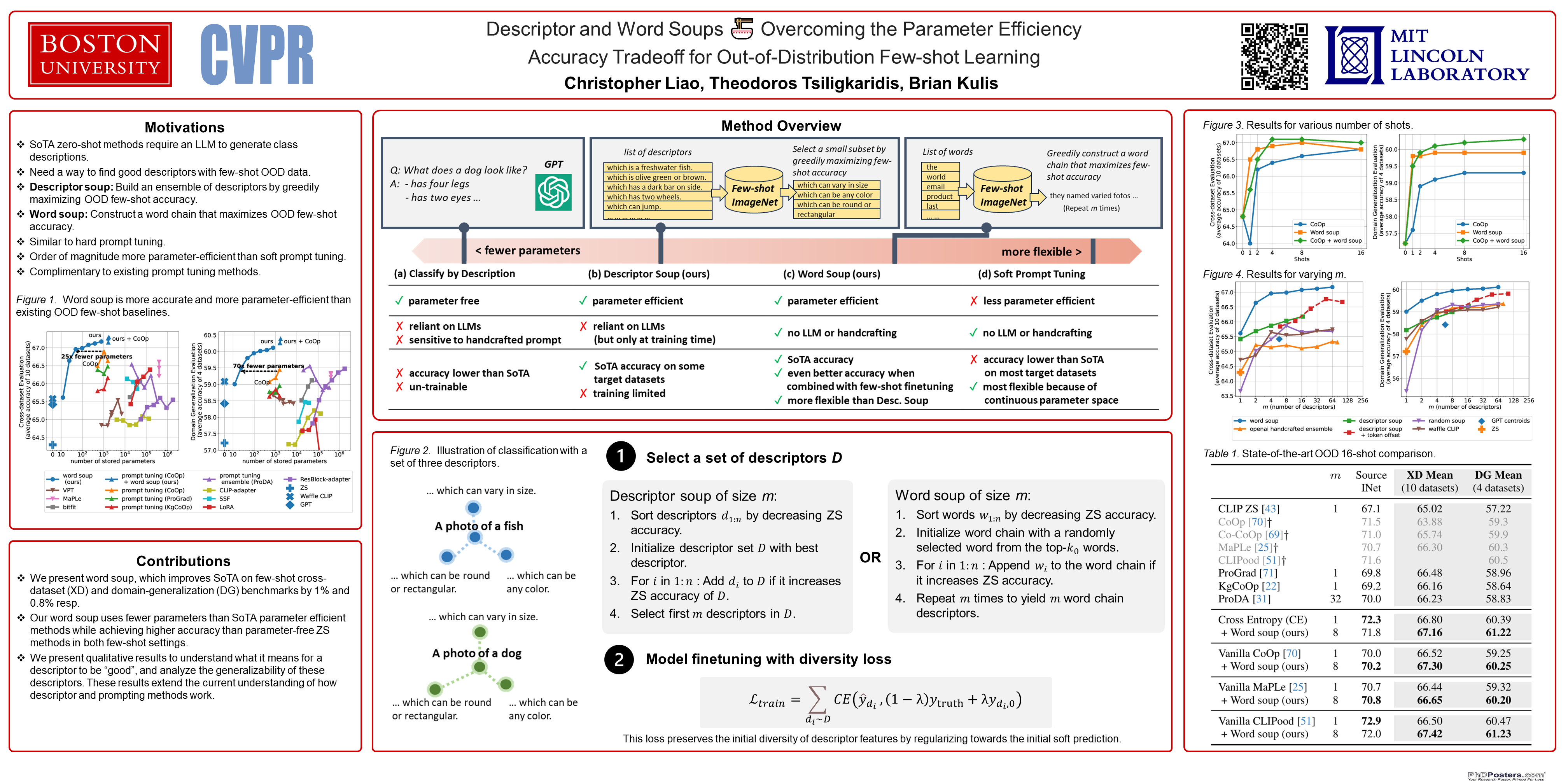
Over the past year, a large body of multimodal research has emerged around zero-shot evaluation using GPT descriptors. These studies boost the zero-shot accuracy of pretrained VL models with an ensemble of label-specific text generated by GPT. A recent study, WaffleCLIP, demonstrated that similar zero-shot accuracy can be achieved with an ensemble of random descriptors. However, both zero-shot methods are un-trainable and consequently sub-optimal when some few-shot out-of-distribution (OOD) training data is available. Inspired by these prior works, we present two more flexible methods called descriptor and word soups, which do not require an LLM at test time and can leverage training data to increase OOD target accuracy. Descriptor soup greedily selects a small set of textual descriptors using generic few-shot training data, then calculates robust class embeddings using the selected descriptors. Word soup greedily assembles a chain of words in a similar manner. Compared to existing few-shot soft prompt tuning methods, word soup requires fewer parameters by construction and less GPU memory, since it does not require backpropagation. Both soups outperform current published few-shot methods, even when combined with SoTA zero-shot methods, on cross-dataset and domain generalization benchmarks. Compared with SoTA prompt and descriptor ensembling methods, such as ProDA and WaffleCLIP, word soup achieves higher OOD accuracy with fewer ensemble members. Please checkout our code: github.com/Chris210634/word_soups