Dispel Darkness for Better Fusion: A Controllable Visual Enhancer based on Cross-modal Conditional Adversarial Learning
{kind=link}
Abstract
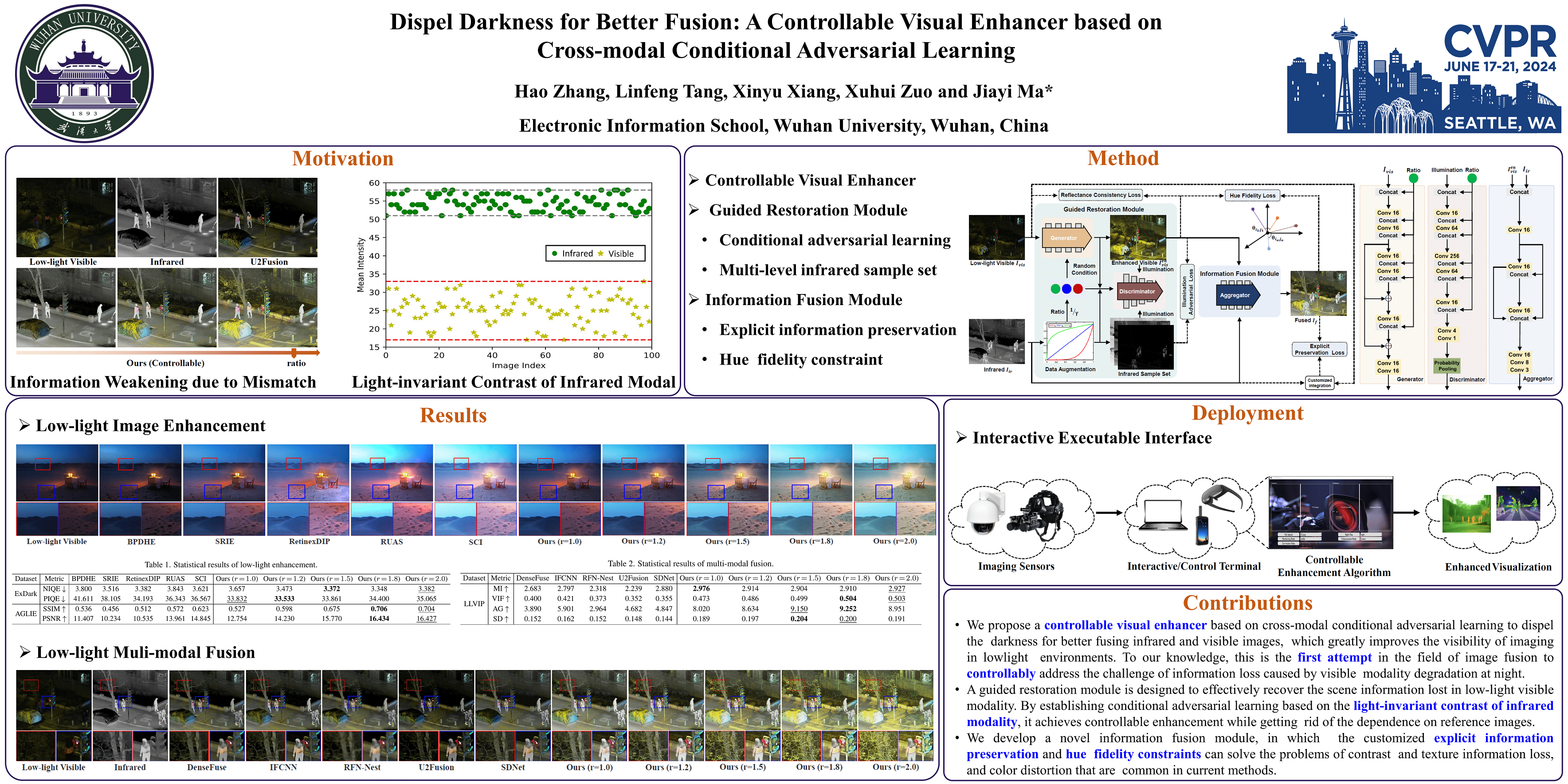
We propose a controllable visual enhancer, named DDBF, which is based on cross-modal conditional adversarial learning and aims to dispel darkness and achieve better visible and infrared modalities fusion. Specifically, a guided restoration module (GRM) is firstly designed to enhance weakened information in the low-light visible modality. The GRM utilizes the light-invariant high-contrast characteristics of the infrared modality as the central target distribution, and constructs a multi-level conditional adversarial sample set to enable continuous controlled brightness enhancement of visible images. Then, we develop an information fusion module (IFM) to integrate the advantageous features of the enhanced visible image and the infrared image. Thanks to customized explicit information preservation and hue fidelity constraints, the IFM produces visually pleasing results with rich textures, significant contrast, and vivid colors. The brightened visible image and the final fused image compose the dual output of our DDBF to meet the diverse visual preferences of users. We evaluate DDBF on the public datasets, achieving state-of-the-art performances of low-light enhancement and information integration that is available for both day and night scenarios. The experiments also demonstrate that our DDBF is effective in improving decision accuracy for object detection and semantic segmentation. Moreover, we offer a user-friendly interface for the convenient application of our model. The code is publicly available at https://github.com/HaoZhang1018/DDBF.