Domain Prompt Learning with Quaternion Networks
 Highlight
Highlight
{kind=link}
Abstract
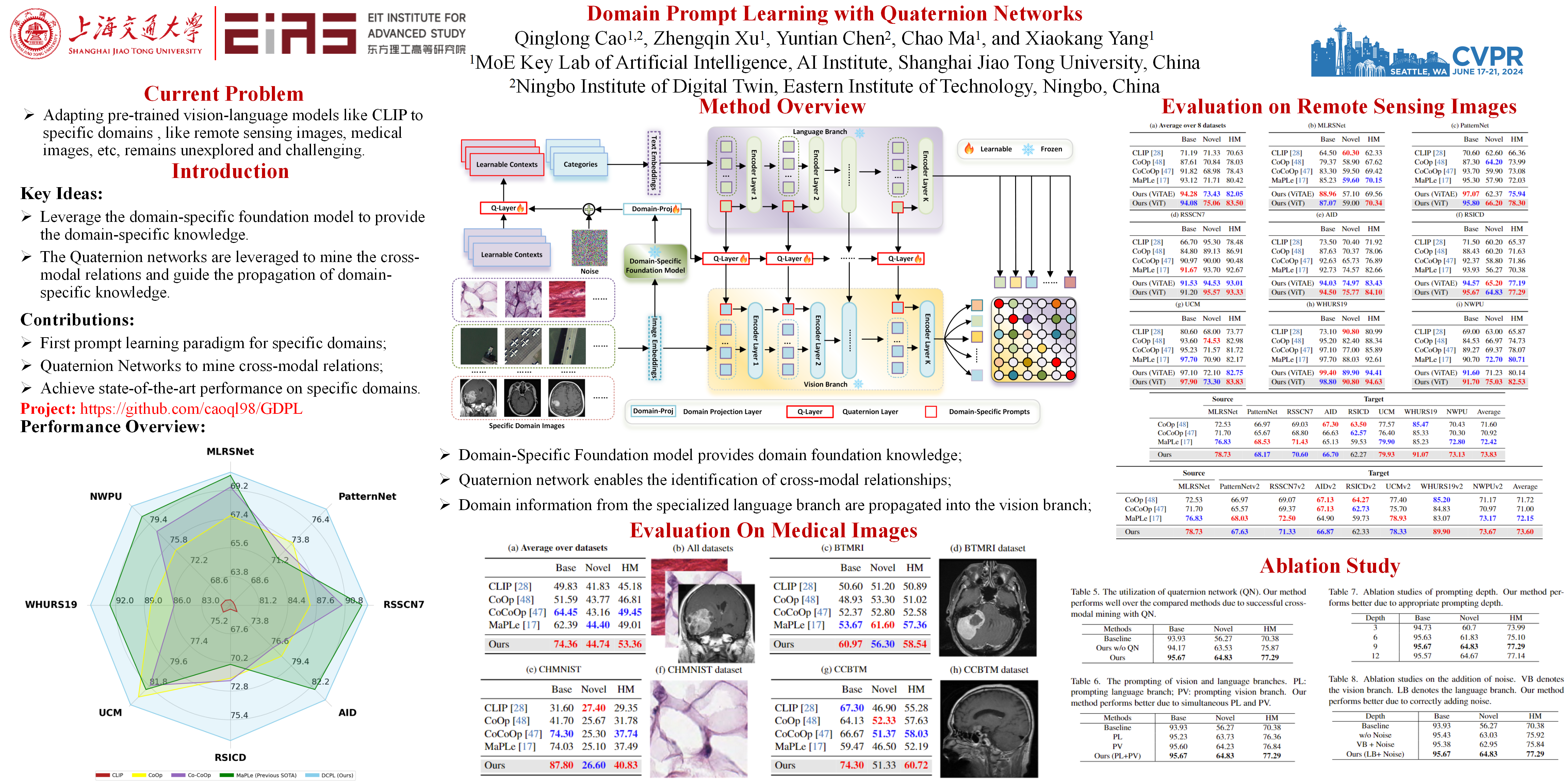
Prompt learning has emerged as an effective and data-efficient technique in large Vision-Language Models (VLMs). However, when adapting VLMs to specialized domains such as remote sensing and medical imaging, domain prompt learning remains underexplored. While large-scale domain-specific foundation models can help tackle this challenge, their concentration on a single vision level makes it challenging to prompt both vision and language modalities. To overcome this, we propose to leverage domain-specific knowledge from domain-specific foundation models to transfer the robust recognition ability of VLMs from generalized to specialized domains, using quaternion networks. Specifically, the proposed method involves using domain-specific vision features from domain-specific foundation models to guide the transformation of generalized contextual embeddings from the language branch into a specialized space within the quaternion networks. Moreover, we present a hierarchical approach that generates vision prompt features by analyzing intermodal relationships between hierarchical language prompt features and domain-specific vision features. In this way, quaternion networks can effectively mine the intermodal relationships in the specific domain, facilitating domain-specific vision-language contrastive learning. Extensive experiments on domain-specific datasets show that our proposed method achieves new state-of-the-art results in prompt learning.