Your Image is My Video: Reshaping the Receptive Field via Image-To-Video Differentiable AutoAugmentation and Fusion
{kind=link}
Abstract
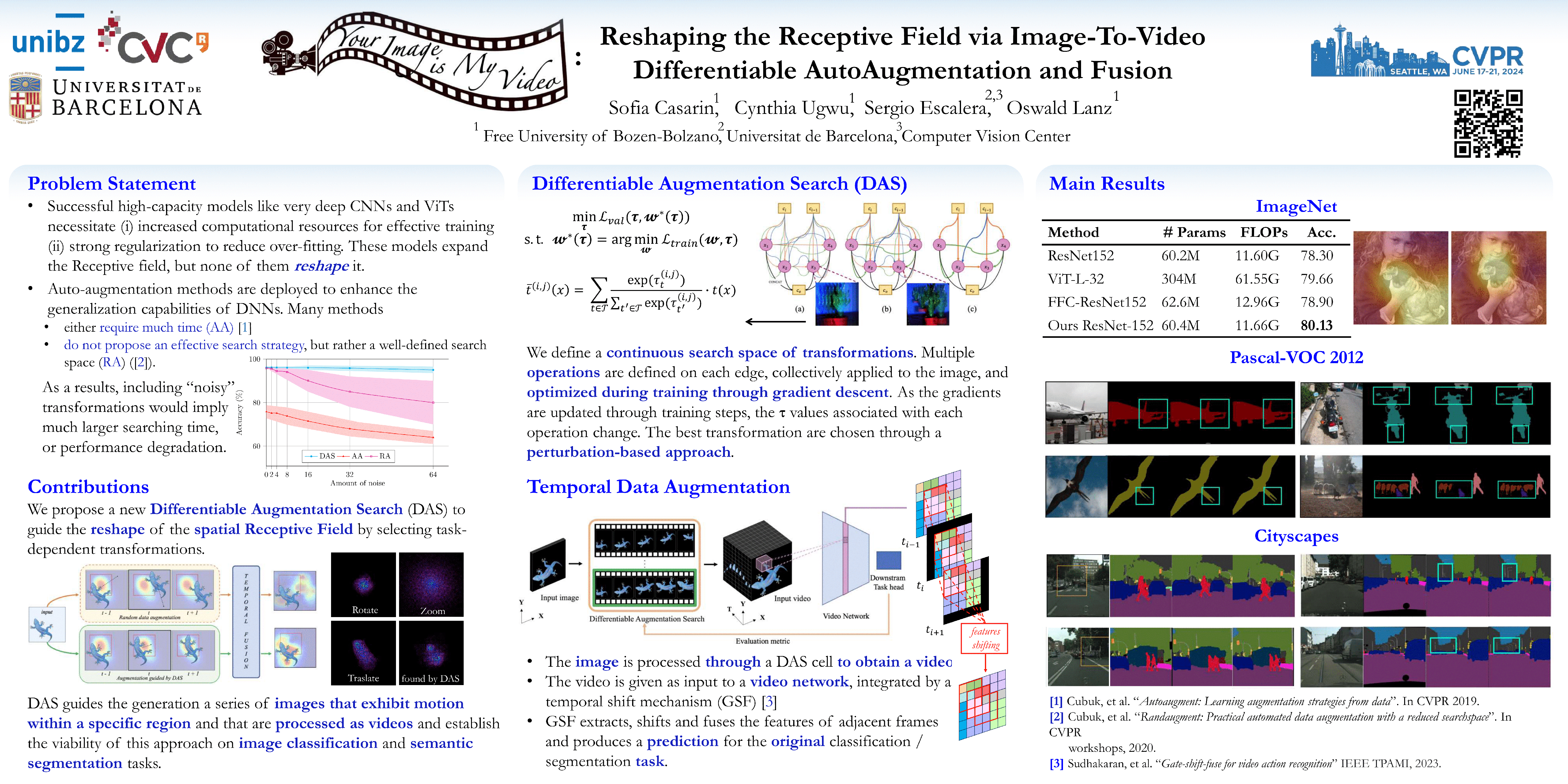
The landscape of deep learning research is moving towards innovative strategies to harness the true potential of data. Traditionally, emphasis has been on scaling model architectures, resulting in large and complex neural networks, which can be difficult to train with limited computational resources. However, independently of the model size, data quality (i.e. amount and variability) is still a major factor that affects model generalization.In this work, we propose a novel technique to exploit available data through the use of automatic data augmentation for the tasks of image classification and semantic segmentation. We introduce the first Differentiable Augmentation Search method (DAS) to generate variations of images that can be processed as videos. Compared to previous approaches, DAS is extremely fast and flexible, allowing the search on very large search spaces in less than a GPU day.Our intuition is that the increased receptive field in the temporal dimension provided by DAS could lead to benefits also to the spatial receptive field. More specifically, we leverage DAS to guide the reshaping of the spatial receptive field by selecting task-dependant transformations.As a result, compared to standard augmentation alternatives, we improve in terms of accuracy on ImageNet, Cifar10, Cifar100, Tiny-ImageNet, Pascal-VOC-2012 and CityScapes datasets when plugging-in our DAS over different light-weight video backbones.