Multiscale Vision Transformers Meet Bipartite Matching for Efficient Single-stage Action Localization
{kind=link}
Abstract
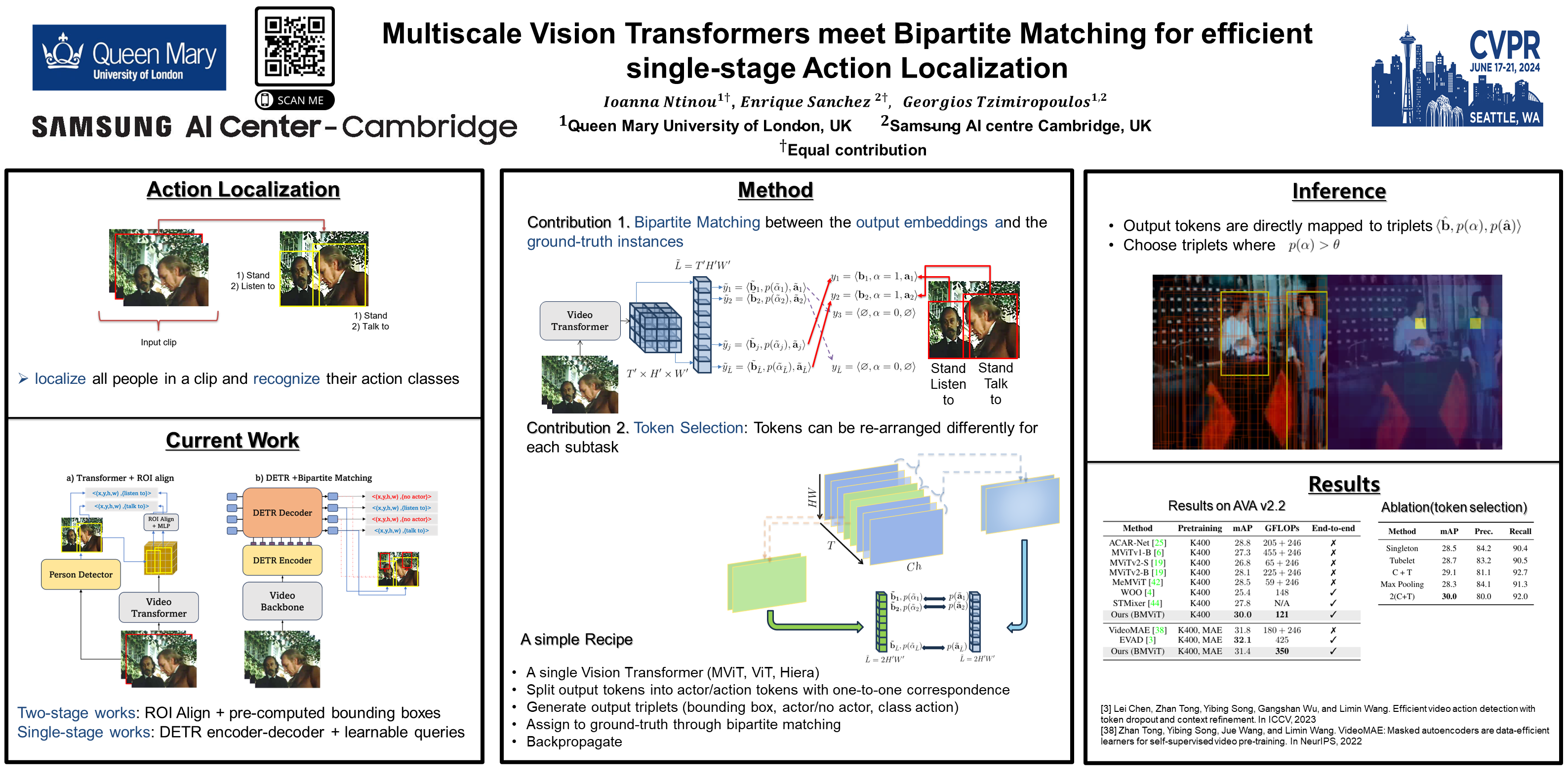
Action Localization is a challenging problem that combines detection and recognition tasks, which are often addressed separately. State-of-the-art methods rely on off-the-shelf bounding box detections pre-computed at high resolution, and propose transformer models that focus on the classification task alone. Such two-stage solutions are prohibitive for real-time deployment. On the other hand, single-stage methods target both tasks by devoting part of the network (generally the backbone) to sharing the majority of the workload, compromising performance for speed. These methods build on adding a DETR head with learnable queries that after cross- and self-attention can be sent to corresponding MLPs for detecting a person’s bounding box and action. However, DETR-like architectures are challenging to train and can incur in big complexity.In this paper, we observe that a straight bipartite matching loss can be applied to the output tokens of a vision transformer. This results in a backbone + MLP architecture that can do both tasks without the need of an extra encoder-decoder head and learnable queries. We show that a single MViTv2-S architecture trained with bipartite matching to perform both tasks surpasses the same MViTv2-S when trained with RoI align on pre-computed bounding boxes. With a careful design of token pooling and the proposed training pipeline, our Bipartite-Matching Vision Transformer model, BMViT, achieves +3 mAP on AVA2.2. w.r.t. the two-stage MViTv2-S counterpart. Code is available athttps://github.com/IoannaNti/BMViT