GOAT-Bench: A Benchmark for Multi-Modal Lifelong Navigation
{kind=link}
Abstract
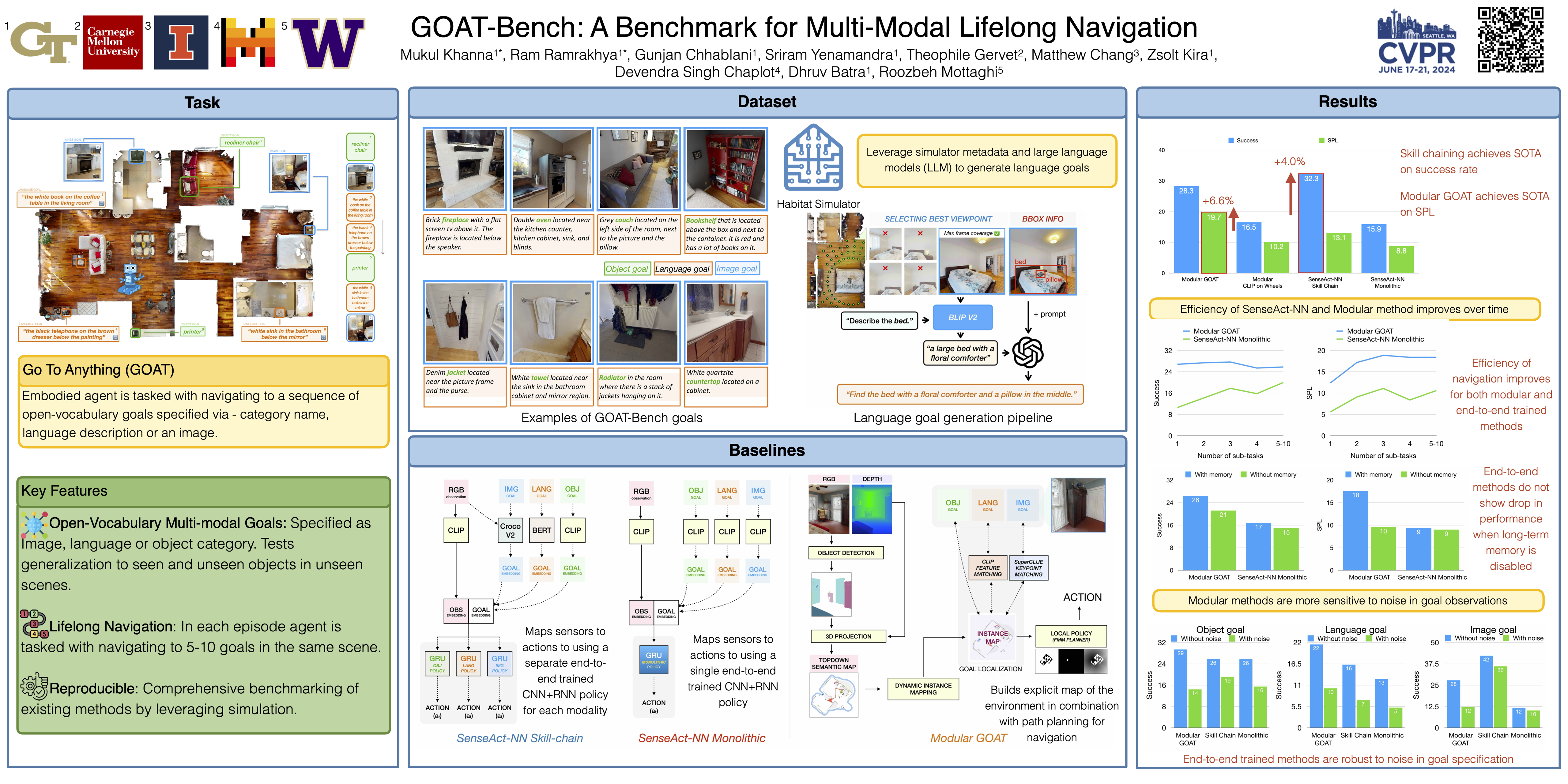
The Embodied AI community has recently made significant strides in visual navigation tasks, exploring targets from 3D coordinates, objects, language description, and images. However, these navigation models often handle only a single input modality as the target. With the progress achieved so far, it is time to move towards universal navigation models capable of handling various goal types, enabling more effective user interaction with robots. To facilitate this goal, we propose GOAT-Bench, a benchmark for the universal navigation task referred to as GO to AnyThing (GOAT). In this task, the agent is directed to navigate to a sequence of targets specified by the category name, language description, or instance image in an open-vocabulary fashion. We benchmark monolithic RL and modular methods on the GOAT task, analyzing their performance across modalities, the role of explicit and implicit scene memories, their robustness to noise in goal specifications, and the impact of memory in lifelong scenarios.