Class Incremental Learning with Multi-Teacher Distillation
{kind=link}
Abstract
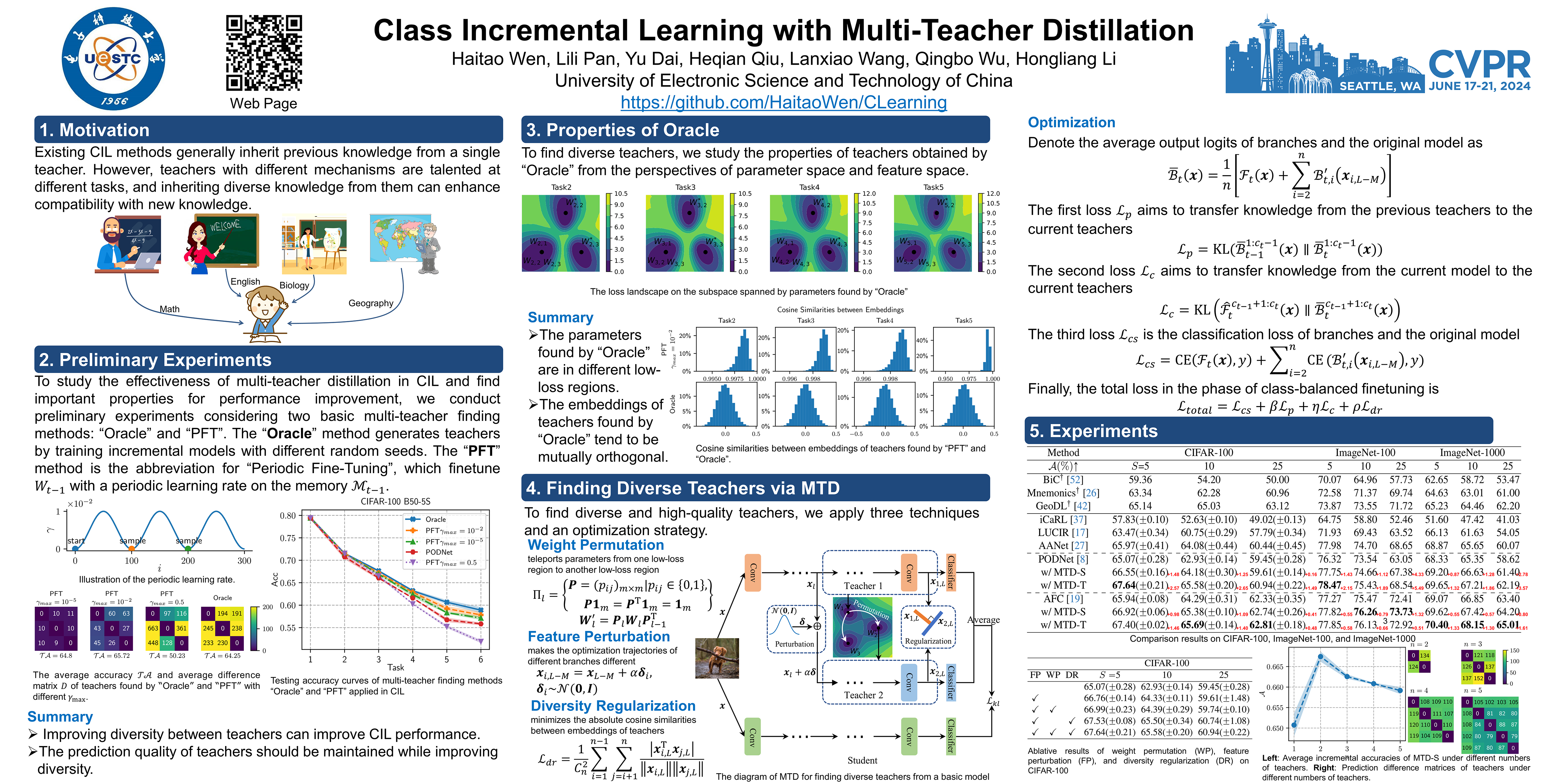
Distillation strategies are currently the primary approaches for mitigating forgetting in class incremental learning (CIL). Existing methods generally inherit previous knowledge from a single teacher. However, teachers with different mechanisms are talented at different tasks, and inheriting diverse knowledge from them can enhance compatibility with new knowledge. In this paper, we propose the MTD method to find multiple diverse teachers for CIL. Specifically, we adopt weight permutation, feature perturbation, and diversity regularization techniques to ensure diverse mechanisms in teachers. To reduce time and memory consumption, each teacher is represented as a small branch in the model. We adapt existing CIL distillation strategies with MTD and extensive experiments on CIFAR-100, ImageNet-100, and ImageNet-1000 show significant performance improvement.