FeatER: An Efficient Network for Human Reconstruction via Feature Map-Based TransformER
{kind=link}
Abstract
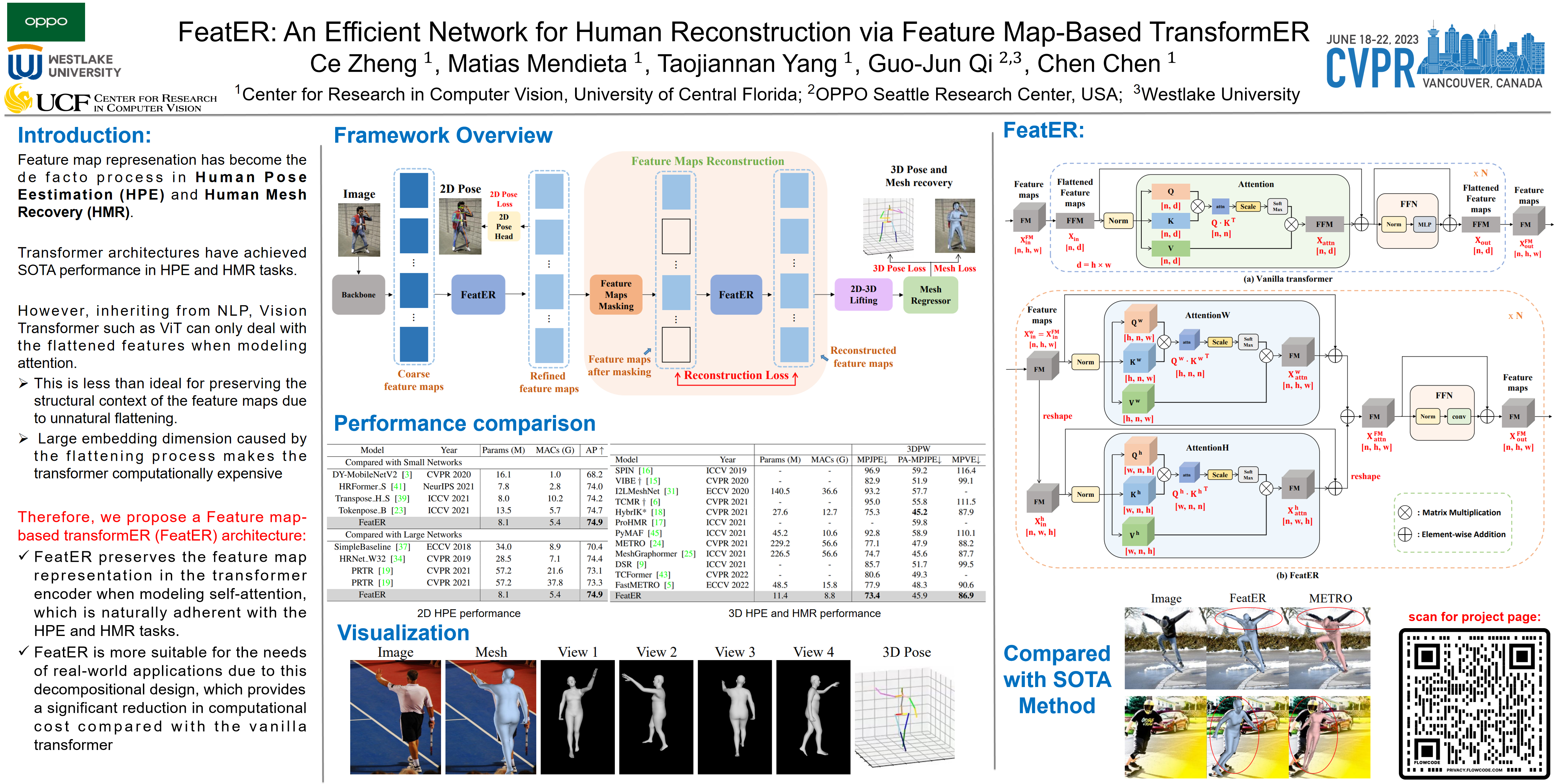
Recently, vision transformers have shown great success in a set of human reconstruction tasks such as 2D human pose estimation (2D HPE), 3D human pose estimation (3D HPE), and human mesh reconstruction (HMR) tasks. In these tasks, feature map representations of the human structural information are often extracted first from the image by a CNN (such as HRNet), and then further processed by transformer to predict the heatmaps (encodes each joint’s location into a feature map with a Gaussian distribution) for HPE or HMR. However, existing transformer architectures are not able to process these feature map inputs directly, forcing an unnatural flattening of the location-sensitive human structural information. Furthermore, much of the performance benefit in recent HPE and HMR methods has come at the cost of ever-increasing computation and memory needs. Therefore, to simultaneously address these problems, we propose FeatER, a novel transformer design which preserves the inherent structure of feature map representations when modeling attention while reducing the memory and computational costs. Taking advantage of FeatER, we build an efficient network for a set of human reconstruction tasks including 2D HPE, 3D HPE, and HMR. A feature map reconstruction module is applied to improve the performance of the estimated human pose and mesh. Extensive experiments demonstrate the effectiveness of FeatER on various human pose and mesh datasets. For instance, FeatER outperforms the SOTA method MeshGraphormer by requiring 5% of Params (total parameters) and 16% of MACs (the Multiply-Accumulate Operations) on Human3.6M and 3DPW datasets. Code will be publicly available.