iCLIP: Bridging Image Classification and Contrastive Language-Image Pre-Training for Visual Recognition
{kind=link}
Abstract
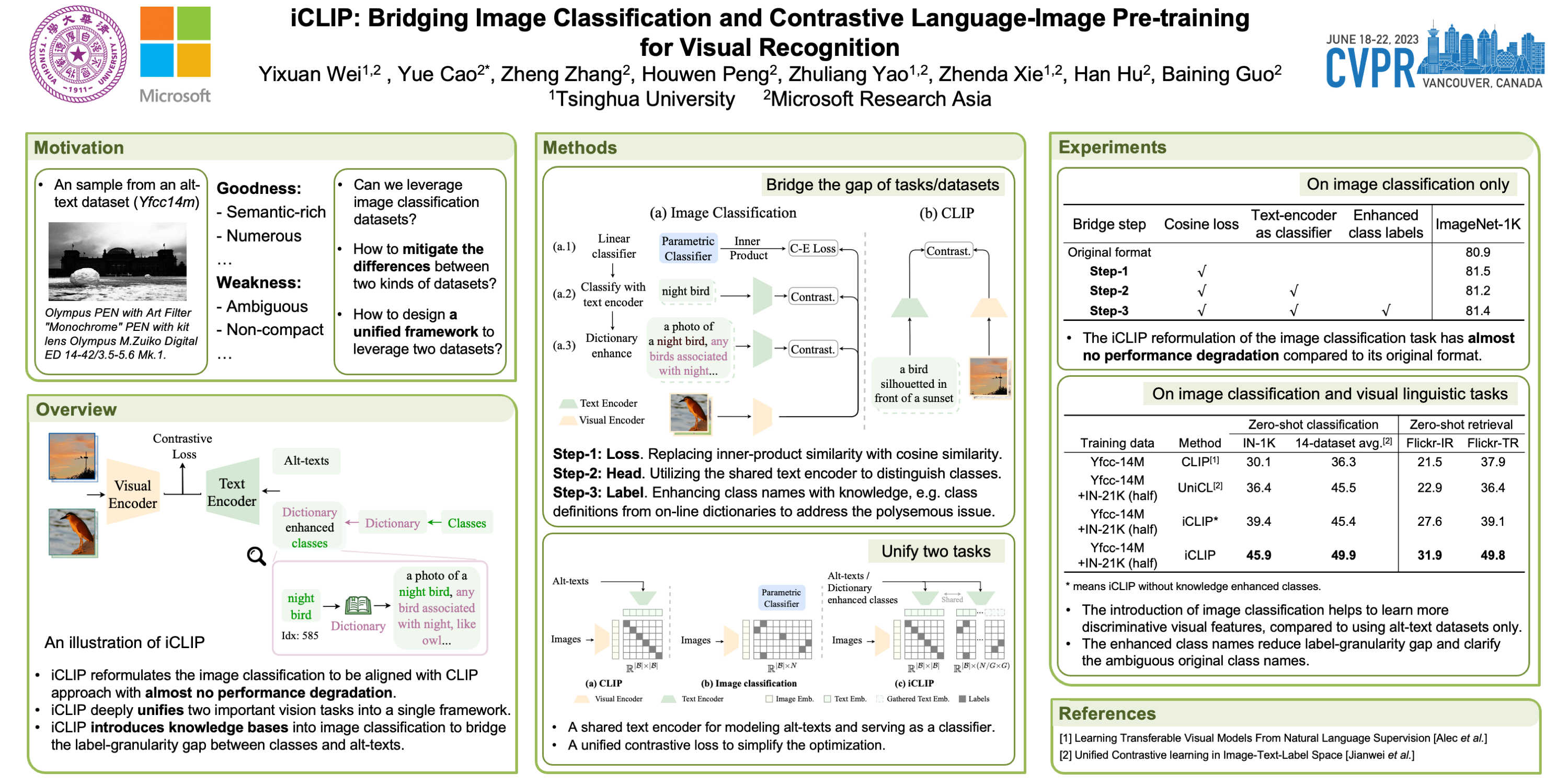
This paper presents a method that effectively combines two prevalent visual recognition methods, i.e., image classification and contrastive language-image pre-training, dubbed iCLIP. Instead of naive multi-task learning that use two separate heads for each task, we fuse the two tasks in a deep fashion that adapts the image classification to share the same formula and the same model weights with the language-image pre-training. To further bridge these two tasks, we propose to enhance the category names in image classification tasks using external knowledge, such as their descriptions in dictionaries. Extensive experiments show that the proposed method combines the advantages of two tasks well: the strong discrimination ability in image classification tasks due to the clear and clean category labels, and the good zero-shot ability in CLIP tasks ascribed to the richer semantics in the text descriptions. In particular, it reaches 82.9% top-1 accuracy on IN-1K, and surpasses CLIPby 1.8%, with similar model size, on zero-shot recognition of Kornblith 12-dataset benchmark. The code and models are publicly available at https://github.com/weiyx16/iCLIP.