A Strong Baseline for Generalized Few-Shot Semantic Segmentation
{kind=link}
Abstract
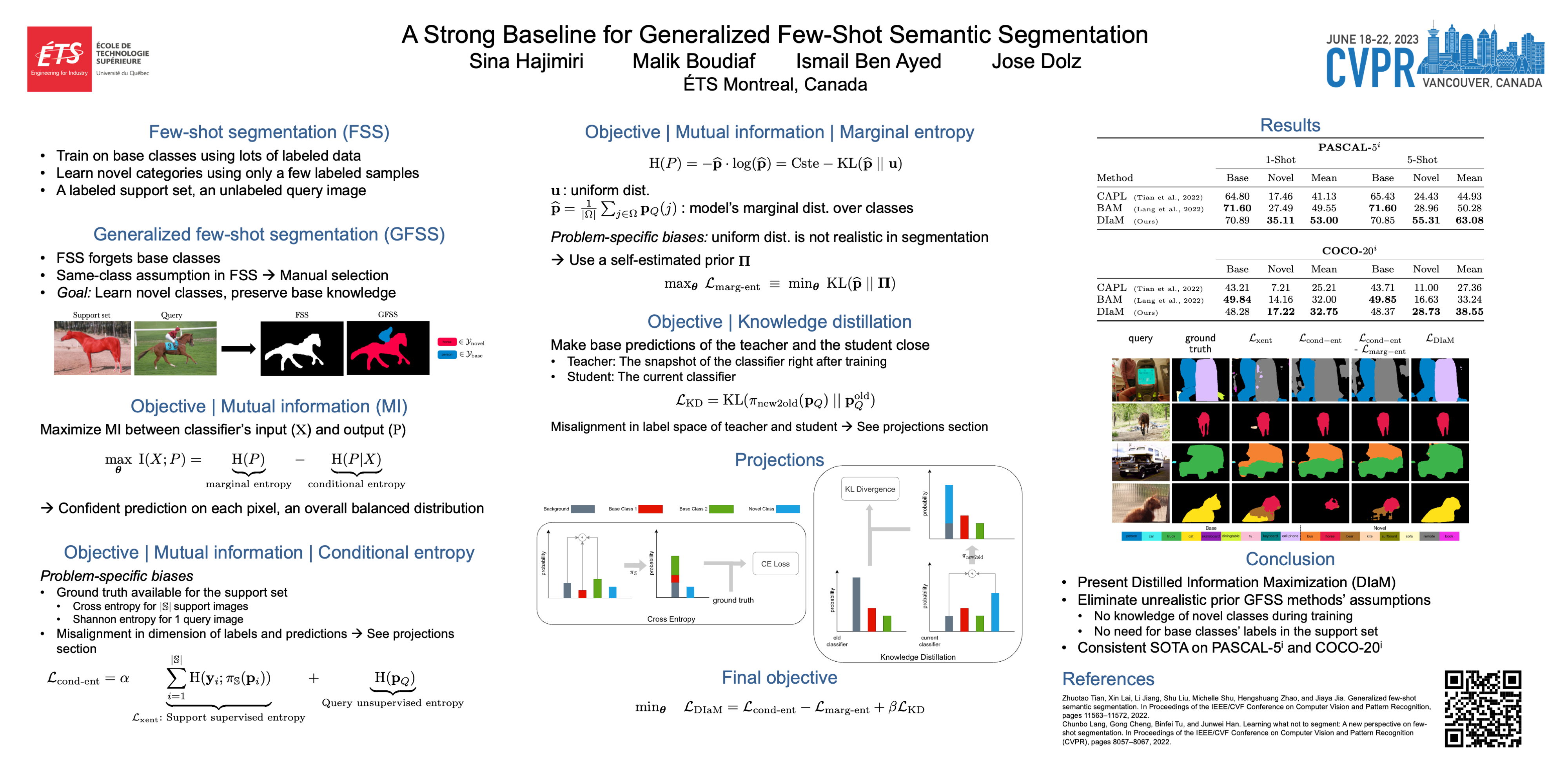
This paper introduces a generalized few-shot segmentation framework with a straightforward training process and an easy-to-optimize inference phase. In particular, we propose a simple yet effective model based on the well-known InfoMax principle, where the Mutual Information (MI) between the learned feature representations and their corresponding predictions is maximized. In addition, the terms derived from our MI-based formulation are coupled with a knowledge distillation term to retain the knowledge on base classes. With a simple training process, our inference model can be applied on top of any segmentation network trained on base classes. The proposed inference yields substantial improvements on the popular few-shot segmentation benchmarks, PASCAL-5^i and COCO-20^i. Particularly, for novel classes, the improvement gains range from 7% to 26% (PASCAL-5^i) and from 3% to 12% (COCO-20^i) in the 1-shot and 5-shot scenarios, respectively. Furthermore, we propose a more challenging setting, where performance gaps are further exacerbated. Our code is publicly available at https://github.com/sinahmr/DIaM.