A Large-Scale Robustness Analysis of Video Action Recognition Models
{kind=link}
Abstract
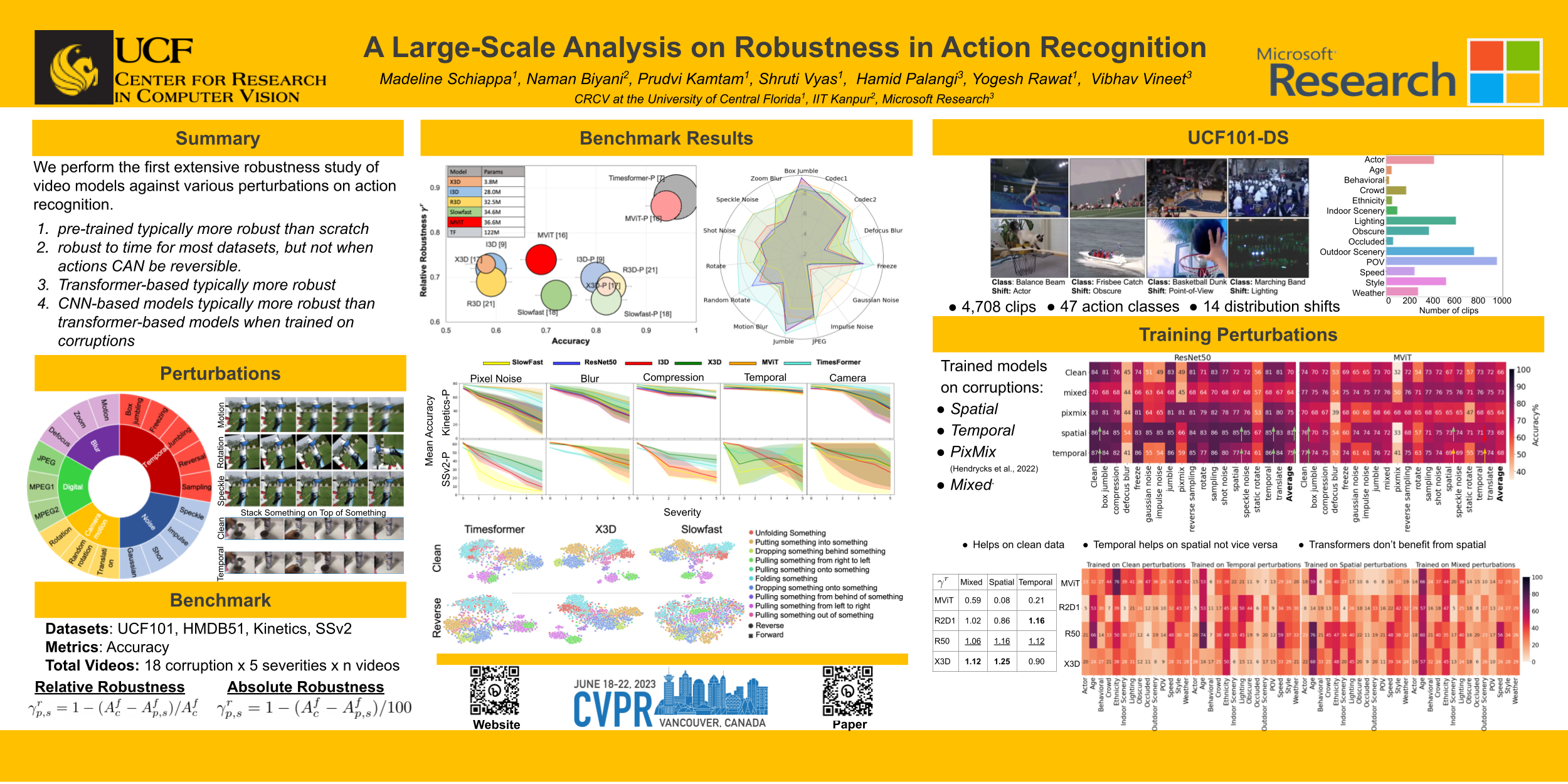
We have seen great progress in video action recognition in recent years. There are several models based on convolutional neural network (CNN) and some recent transformer based approaches which provide top performance on existing benchmarks. In this work, we perform a large-scale robustness analysis of these existing models for video action recognition. We focus on robustness against real-world distribution shift perturbations instead of adversarial perturbations. We propose four different benchmark datasets, HMDB51-P, UCF101-P, Kinetics400-P, and SSv2-P to perform this analysis. We study robustness of six state-of-the-art action recognition models against 90 different perturbations. The study reveals some interesting findings, 1) Transformer based models are consistently more robust compared to CNN based models, 2) Pre-training improves robustness for Transformer based models more than CNN based models, and 3) All of the studied models are robust to temporal perturbations for all datasets but SSv2; suggesting the importance of temporal information for action recognition varies based on the dataset and activities. Next, we study the role of augmentations in model robustness and present a real-world dataset, UCF101-DS, which contains realistic distribution shifts, to further validate some of these findings. We believe this study will serve as a benchmark for future research in robust video action recognition.