AShapeFormer: Semantics-Guided Object-Level Active Shape Encoding for 3D Object Detection via Transformers
{kind=link}
Abstract
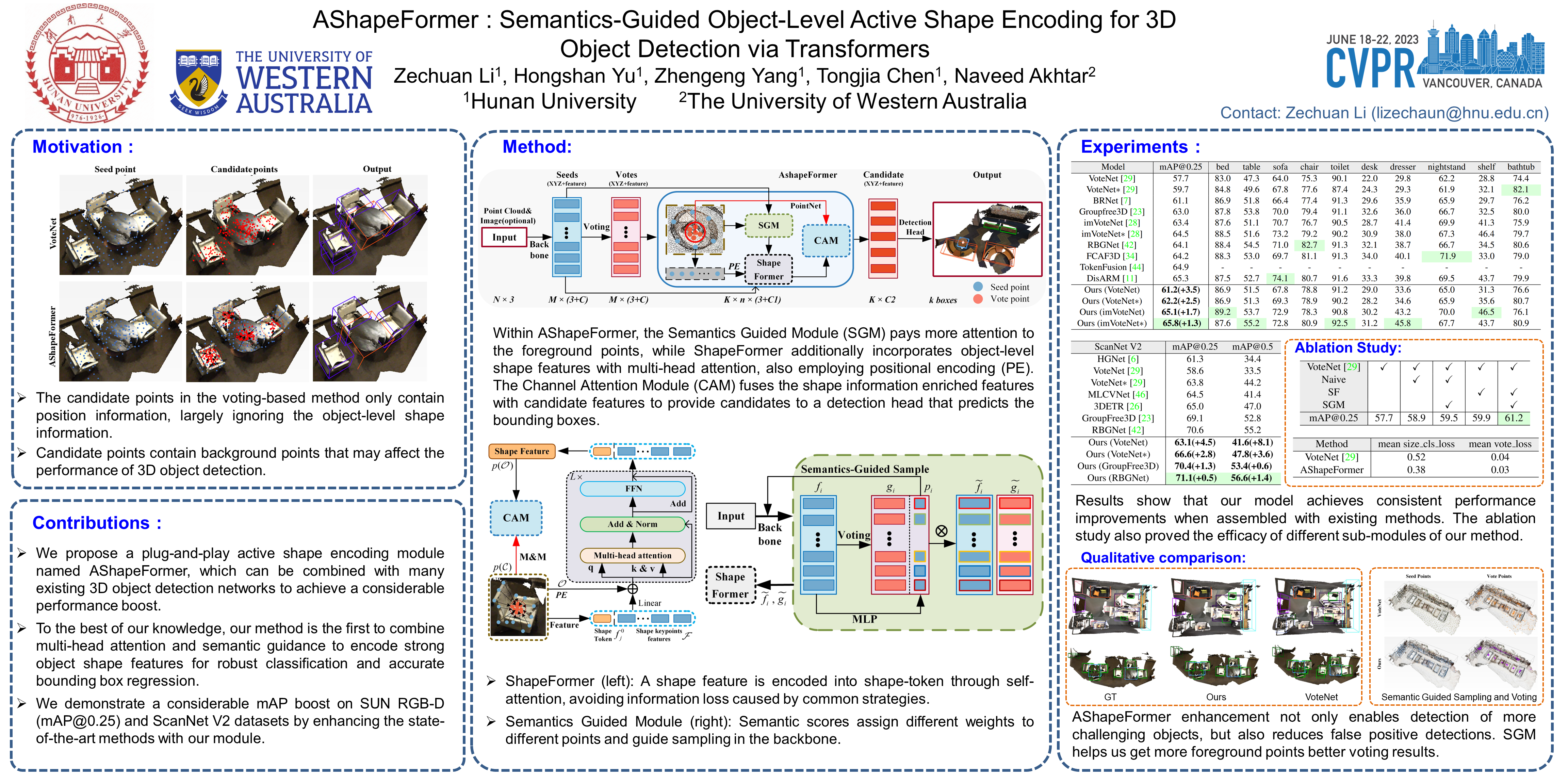
3D object detection techniques commonly follow a pipeline that aggregates predicted object central point features to compute candidate points. However, these candidate points contain only positional information, largely ignoring the object-level shape information. This eventually leads to sub-optimal 3D object detection. In this work, we propose AShapeFormer, a semantics-guided object-level shape encoding module for 3D object detection. This is a plug-n-play module that leverages multi-head attention to encode object shape information. We also propose shape tokens and object-scene positional encoding to ensure that the shape information is fully exploited. Moreover, we introduce a semantic guidance sub-module to sample more foreground points and suppress the influence of background points for a better object shape perception. We demonstrate a straightforward enhancement of multiple existing methods with our AShapeFormer. Through extensive experiments on the popular SUN RGB-D and ScanNetV2 dataset, we show that our enhanced models are able to outperform the baselines by a considerable absolute margin of up to 8.1%. Code will be available at https://github.com/ZechuanLi/AShapeFormer