Distilling Cross-Temporal Contexts for Continuous Sign Language Recognition
{kind=link}
Abstract
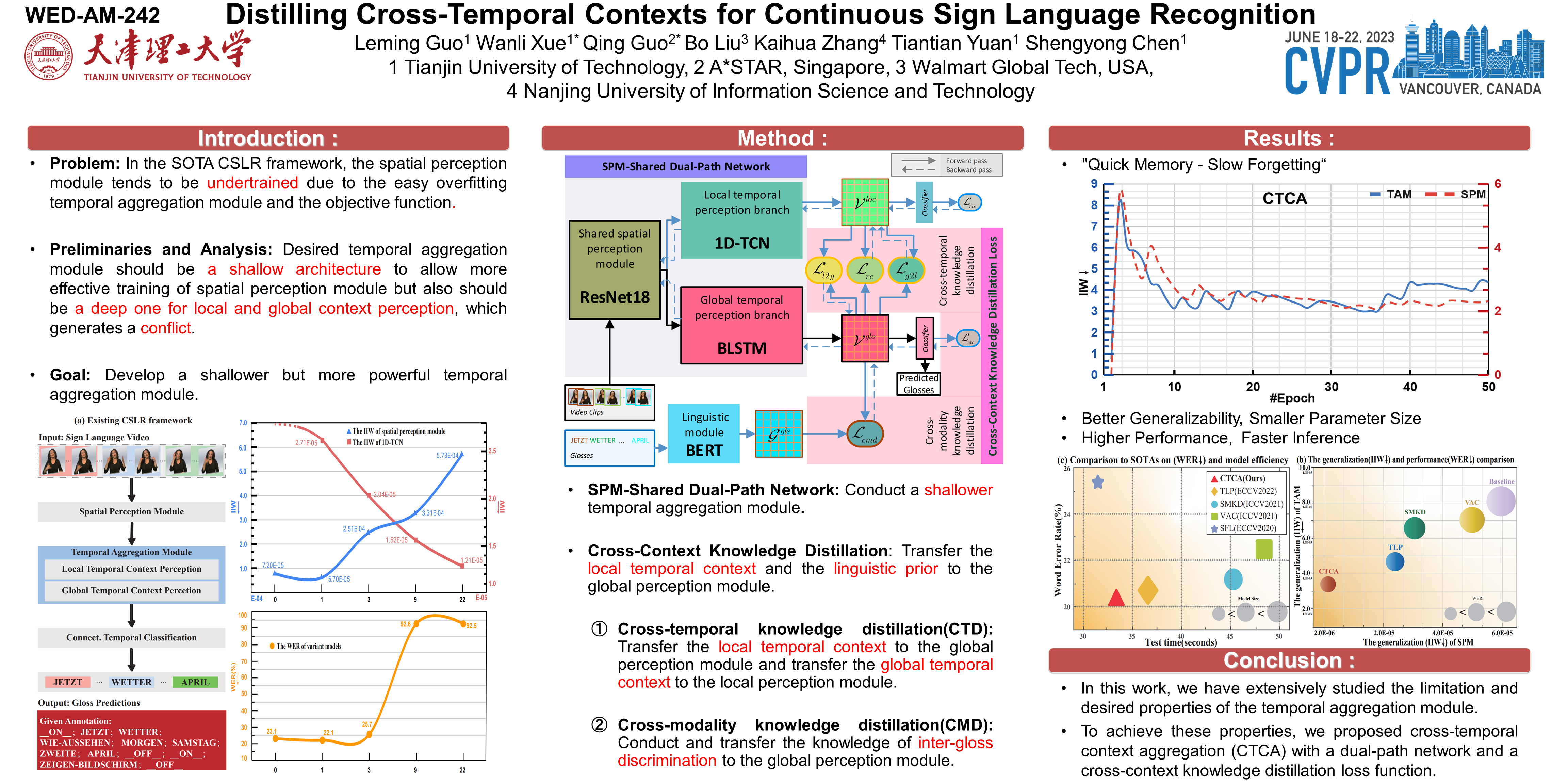
Continuous sign language recognition (CSLR) aims to recognize glosses in a sign language video. State-of-the-art methods typically have two modules, a spatial perception module and a temporal aggregation module, which are jointly learned end-to-end. Existing results in [9,20,25,36] have indicated that, as the frontal component of the overall model, the spatial perception module used for spatial feature extraction tends to be insufficiently trained. In this paper, we first conduct empirical studies and show that a shallow temporal aggregation module allows more thorough training of the spatial perception module. However, a shallow temporal aggregation module cannot well capture both local and global temporal context information in sign language. To address this dilemma, we propose a cross-temporal context aggregation (CTCA) model. Specifically, we build a dual-path network that contains two branches for perceptions of local temporal context and global temporal context. We further design a cross-context knowledge distillation learning objective to aggregate the two types of context and the linguistic prior. The knowledge distillation enables the resultant one-branch temporal aggregation module to perceive local-global temporal and semantic context. This shallow temporal perception module structure facilitates spatial perception module learning. Extensive experiments on challenging CSLR benchmarks demonstrate that our method outperforms all state-of-the-art methods.