MixMAE: Mixed and Masked Autoencoder for Efficient Pretraining of Hierarchical Vision Transformers
{kind=link}
Abstract
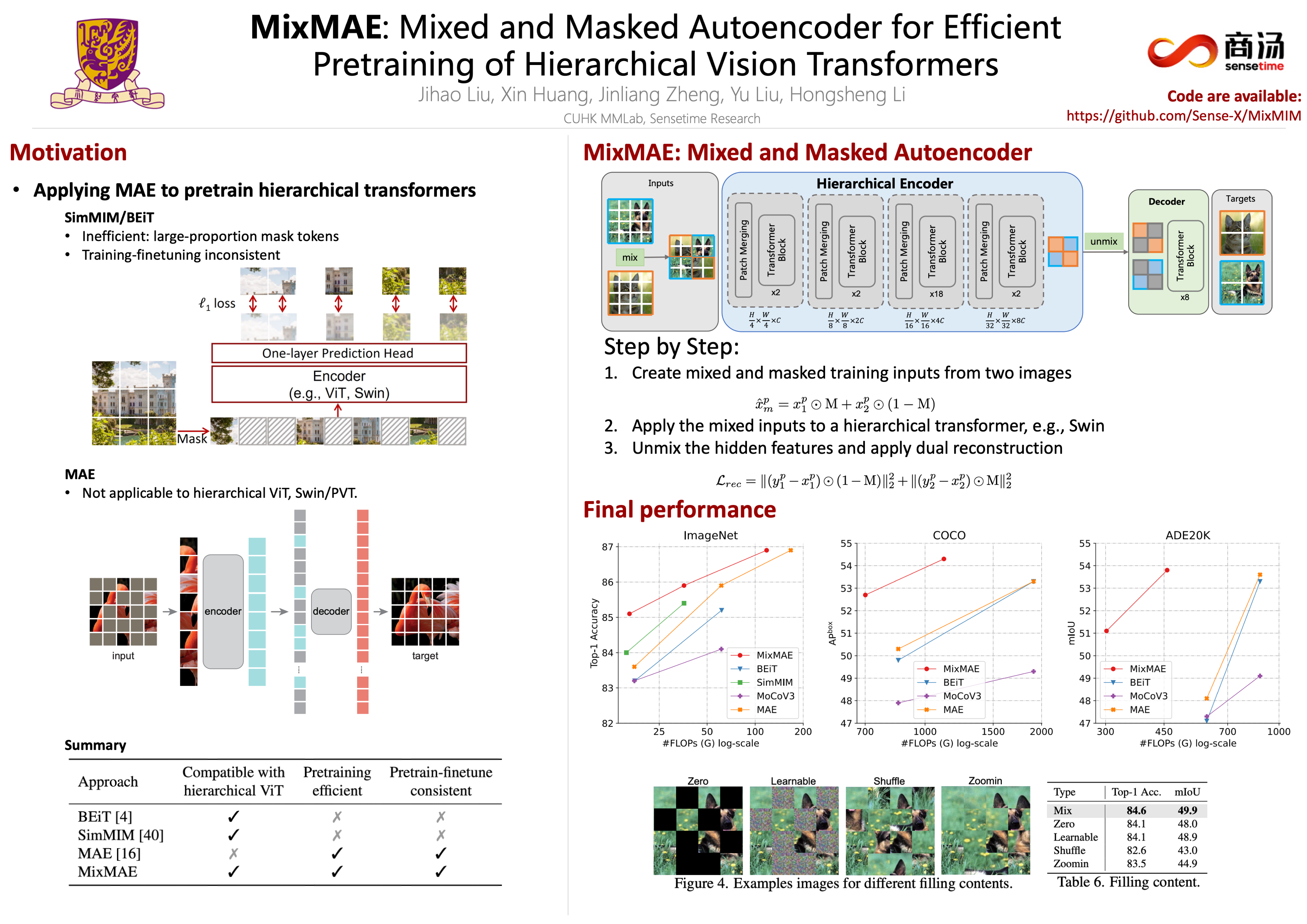
In this paper, we propose Mixed and Masked AutoEncoder (MixMAE), a simple but efficient pretraining method that is applicable to various hierarchical Vision Transformers. Existing masked image modeling (MIM) methods for hierarchical Vision Transformers replace a random subset of input tokens with a special [MASK] symbol and aim at reconstructing original image tokens from the corrupted image. However, we find that using the [MASK] symbol greatly slows down the training and causes pretraining-finetuning inconsistency, due to the large masking ratio (e.g., 60% in SimMIM). On the other hand, MAE does not introduce [MASK] tokens at its encoder at all but is not applicable for hierarchical Vision Transformers. To solve the issue and accelerate the pretraining of hierarchical models, we replace the masked tokens of one image with visible tokens of another image, i.e., creating a mixed image. We then conduct dual reconstruction to reconstruct the two original images from the mixed input, which significantly improves efficiency. While MixMAE can be applied to various hierarchical Transformers, this paper explores using Swin Transformer with a large window size and scales up to huge model size (to reach 600M parameters). Empirical results demonstrate that MixMAE can learn high-quality visual representations efficiently. Notably, MixMAE with Swin-B/W14 achieves 85.1% top-1 accuracy on ImageNet-1K by pretraining for 600 epochs. Besides, its transfer performances on the other 6 datasets show that MixMAE has better FLOPs / performance tradeoff than previous popular MIM methods.