Improving Visual Representation Learning Through Perceptual Understanding
{kind=link}
Abstract
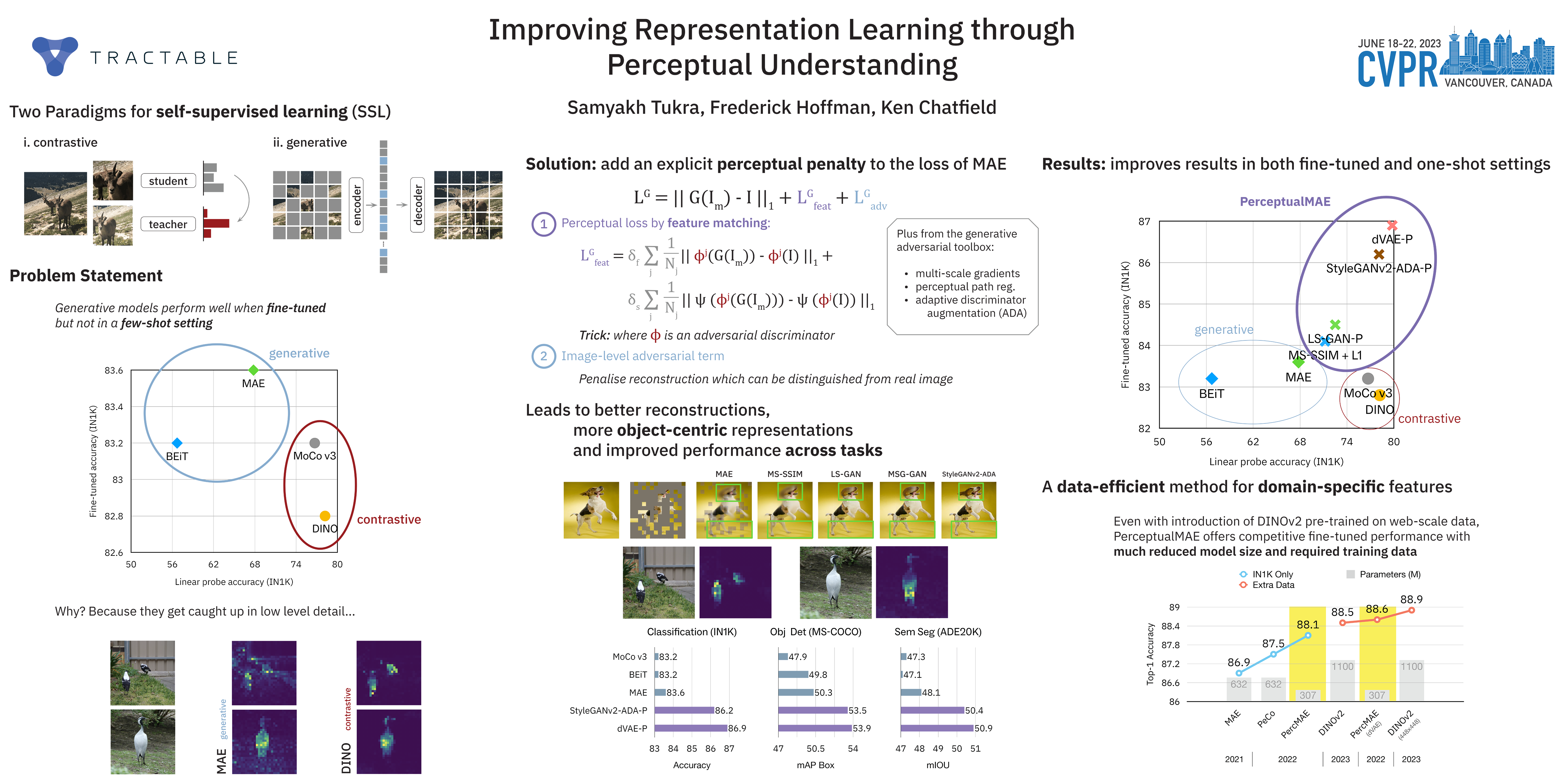
We present an extension to masked autoencoders (MAE) which improves on the representations learnt by the model by explicitly encouraging the learning of higher scene-level features. We do this by: (i) the introduction of a perceptual similarity term between generated and real images (ii) incorporating several techniques from the adversarial training literature including multi-scale training and adaptive discriminator augmentation. The combination of these results in not only better pixel reconstruction but also representations which appear to capture better higher-level details within images. More consequentially, we show how our method, Perceptual MAE, leads to better performance when used for downstream tasks outperforming previous methods. We achieve 78.1% top-1 accuracy linear probing on ImageNet-1K and up to 88.1% when fine-tuning, with similar results for other downstream tasks, all without use of additional pre-trained models or data.