Masked Video Distillation: Rethinking Masked Feature Modeling for Self-Supervised Video Representation Learning
{kind=link}
Abstract
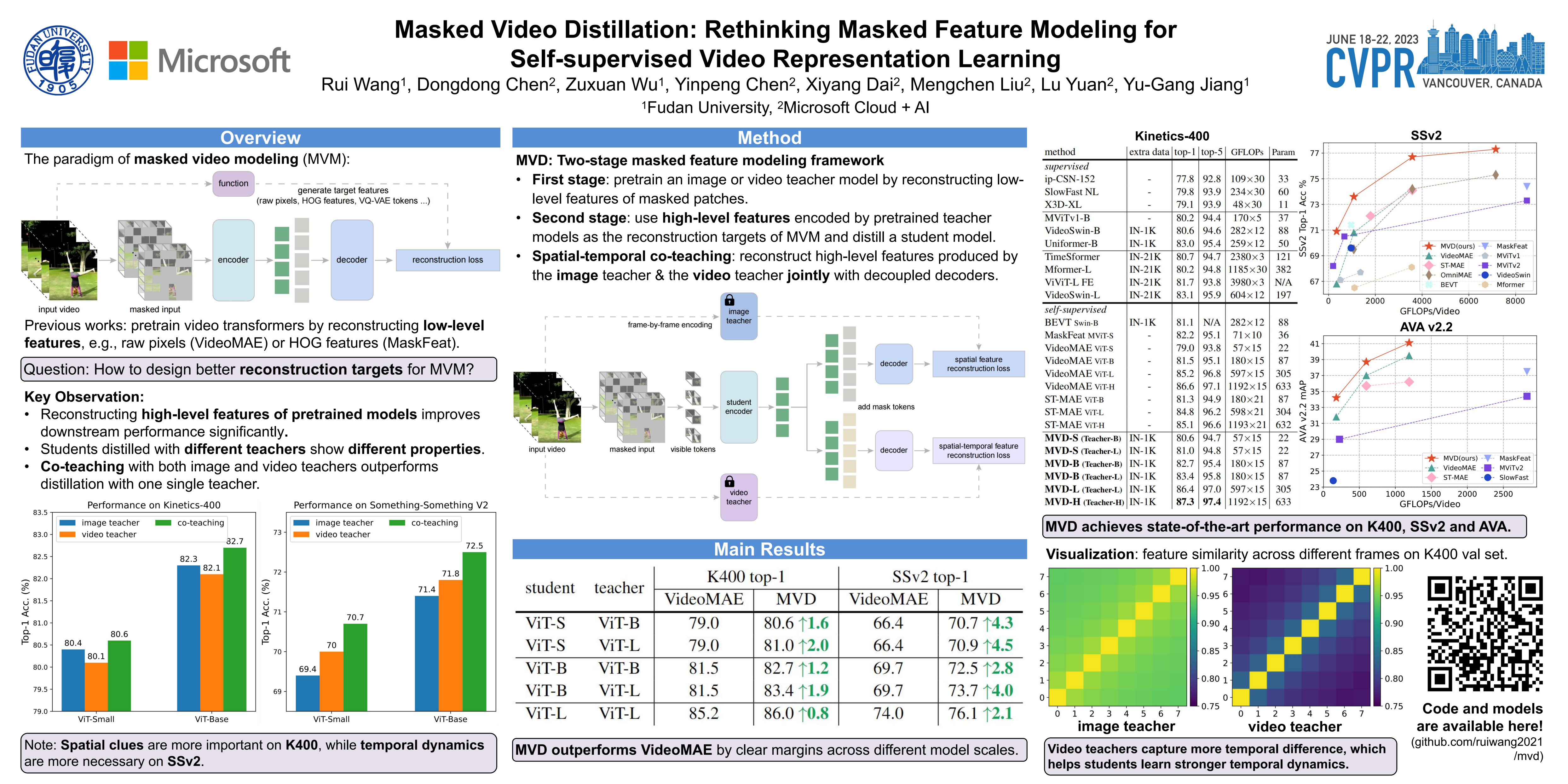
Benefiting from masked visual modeling, self-supervised video representation learning has achieved remarkable progress. However, existing methods focus on learning representations from scratch through reconstructing low-level features like raw pixel values. In this paper, we propose masked video distillation (MVD), a simple yet effective two-stage masked feature modeling framework for video representation learning: firstly we pretrain an image (or video) model by recovering low-level features of masked patches, then we use the resulting features as targets for masked feature modeling. For the choice of teacher models, we observe that students taught by video teachers perform better on temporally-heavy video tasks, while image teachers transfer stronger spatial representations for spatially-heavy video tasks. Visualization analysis also indicates different teachers produce different learned patterns for students. To leverage the advantage of different teachers, we design a spatial-temporal co-teaching method for MVD. Specifically, we distill student models from both video teachers and image teachers by masked feature modeling. Extensive experimental results demonstrate that video transformers pretrained with spatial-temporal co-teaching outperform models distilled with a single teacher on a multitude of video datasets. Our MVD with vanilla ViT achieves state-of-the-art performance compared with previous methods on several challenging video downstream tasks. For example, with the ViT-Large model, our MVD achieves 86.4% and 76.7% Top-1 accuracy on Kinetics-400 and Something-Something-v2, outperforming VideoMAE by 1.2% and 2.4% respectively. When a larger ViT-Huge model is adopted, MVD achieves the state-of-the-art performance with 77.3% Top-1 accuracy on Something-Something-v2. Code will be available at https://github.com/ruiwang2021/mvd.