Master: Meta Style Transformer for Controllable Zero-Shot and Few-Shot Artistic Style Transfer
{kind=link}
Abstract
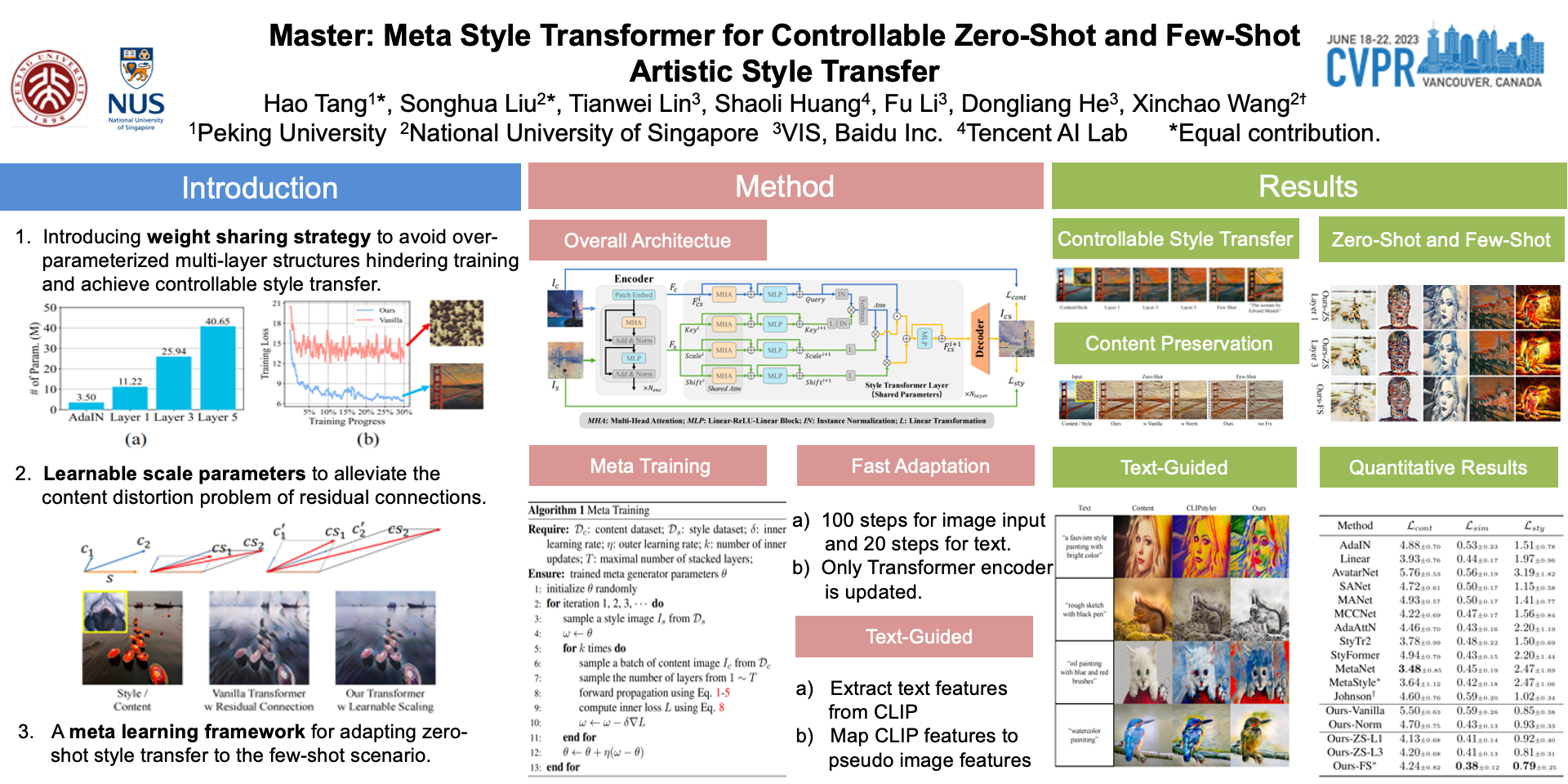
Transformer-based models achieve favorable performance in artistic style transfer recently thanks to its global receptive field and powerful multi-head/layer attention operations. Nevertheless, the over-paramerized multi-layer structure increases parameters significantly and thus presents a heavy burden for training. Moreover, for the task of style transfer, vanilla Transformer that fuses content and style features by residual connections is prone to content-wise distortion. In this paper, we devise a novel Transformer model termed as Master specifically for style transfer. On the one hand, in the proposed model, different Transformer layers share a common group of parameters, which (1) reduces the total number of parameters, (2) leads to more robust training convergence, and (3) is readily to control the degree of stylization via tuning the number of stacked layers freely during inference. On the other hand, different from the vanilla version, we adopt a learnable scaling operation on content features before content-style feature interaction, which better preserves the original similarity between a pair of content features while ensuring the stylization quality. We also propose a novel meta learning scheme for the proposed model so that it can not only work in the typical setting of arbitrary style transfer, but also adaptable to the few-shot setting, by only fine-tuning the Transformer encoder layer in the few-shot stage for one specific style. Text-guided few-shot style transfer is firstly achieved with the proposed framework. Extensive experiments demonstrate the superiority of Master under both zero-shot and few-shot style transfer settings.