Combining Implicit-Explicit View Correlation for Light Field Semantic Segmentation
{kind=link}
Abstract
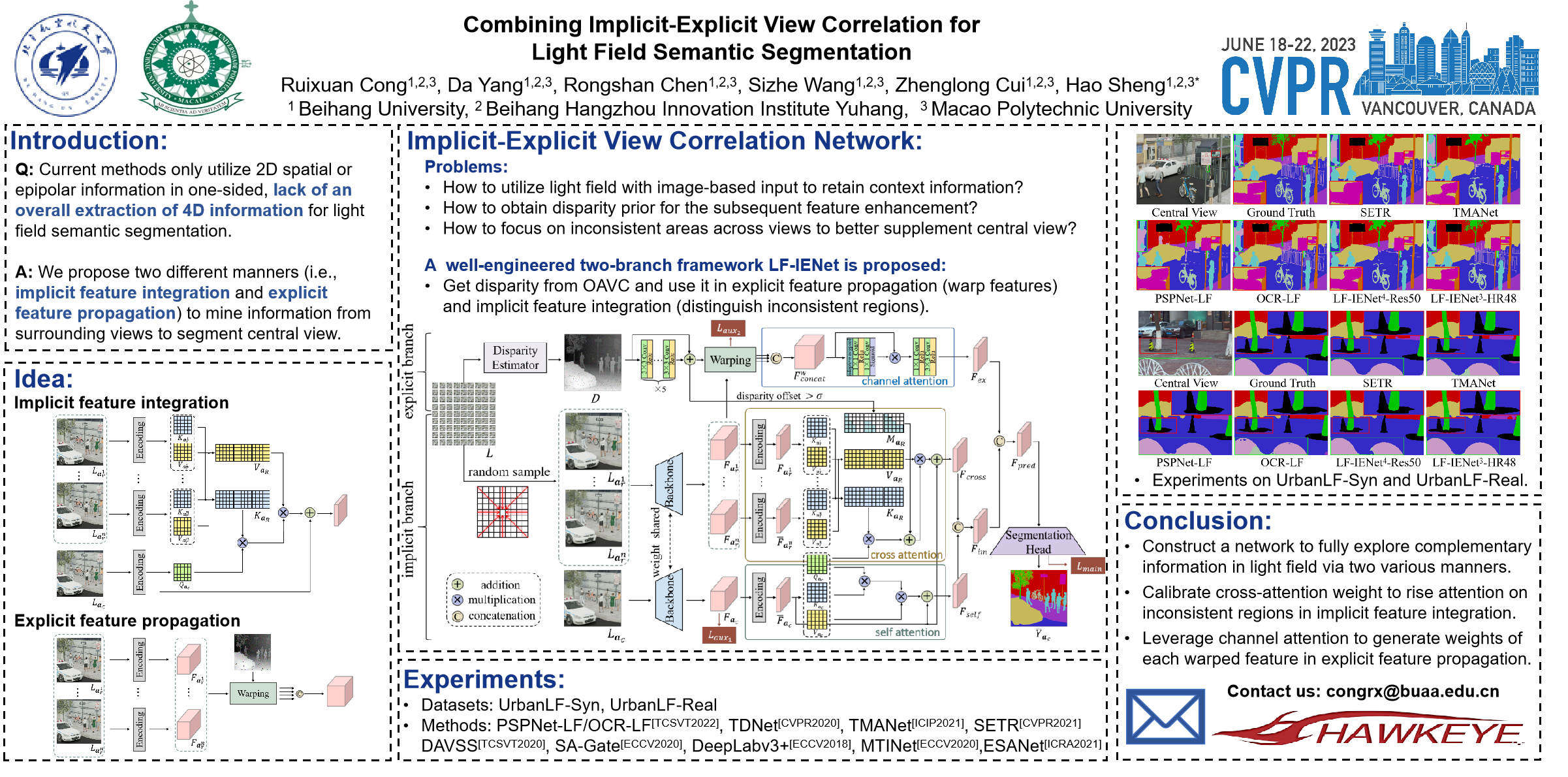
Since light field simultaneously records spatial information and angular information of light rays, it is considered to be beneficial for many potential applications, and semantic segmentation is one of them. The regular variation of image information across views facilitates a comprehensive scene understanding. However, in the case of limited memory, the high-dimensional property of light field makes the problem more intractable than generic semantic segmentation, manifested in the difficulty of fully exploiting the relationships among views while maintaining contextual information in single view. In this paper, we propose a novel network called LF-IENet for light field semantic segmentation. It contains two different manners to mine complementary information from surrounding views to segment central view. One is implicit feature integration that leverages attention mechanism to compute inter-view and intra-view similarity to modulate features of central view. The other is explicit feature propagation that directly warps features of other views to central view under the guidance of disparity. They complement each other and jointly realize complementary information fusion across views in light field. The proposed method achieves outperforming performance on both real-world and synthetic light field datasets, demonstrating the effectiveness of this new architecture.