Mod-Squad: Designing Mixtures of Experts As Modular Multi-Task Learners
{kind=link}
Abstract
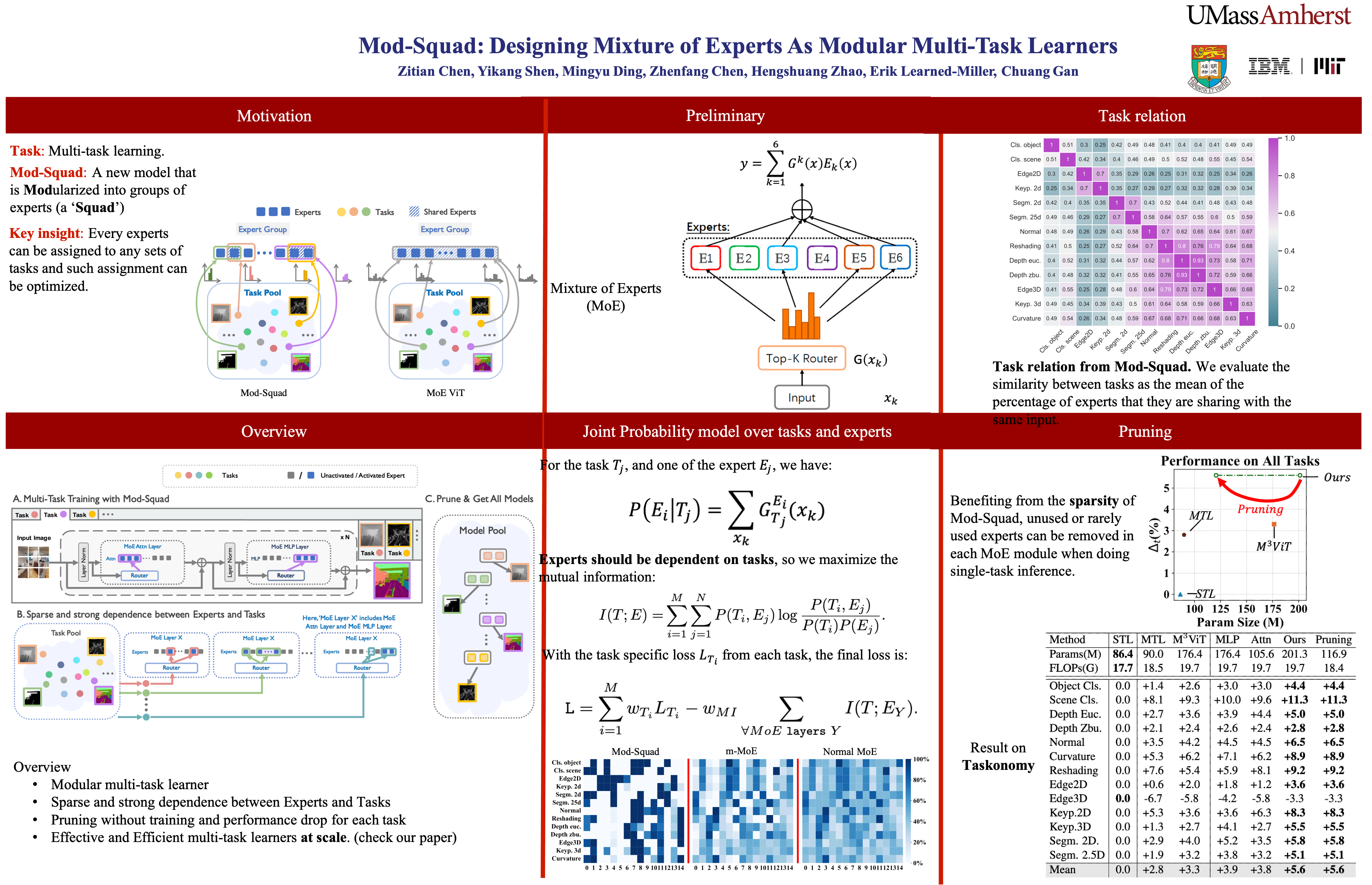
Optimization in multi-task learning (MTL) is more challenging than single-task learning (STL), as the gradient from different tasks can be contradictory. When tasks are related, it can be beneficial to share some parameters among them (cooperation). However, some tasks require additional parameters with expertise in a specific type of data or discrimination (specialization). To address the MTL challenge, we propose Mod-Squad, a new model that is Modularized into groups of experts (a ‘Squad’). This structure allows us to formalize cooperation and specialization as the process of matching experts and tasks. We optimize this matching process during the training of a single model. Specifically, we incorporate mixture of experts (MoE) layers into a transformer model, with a new loss that incorporates the mutual dependence between tasks and experts. As a result, only a small set of experts are activated for each task. This prevents the sharing of the entire backbone model between all tasks, which strengthens the model, especially when the training set size and the number of tasks scale up. More interestingly, for each task, we can extract the small set of experts as a standalone model that maintains the same performance as the large model. Extensive experiments on the Taskonomy dataset with 13 vision tasks and the PASCALContext dataset with 5 vision tasks show the superiority of our approach. The project page can be accessed at https://vis-www.cs.umass.edu/mod-squad.