MoDi: Unconditional Motion Synthesis From Diverse Data
{kind=link}
Abstract
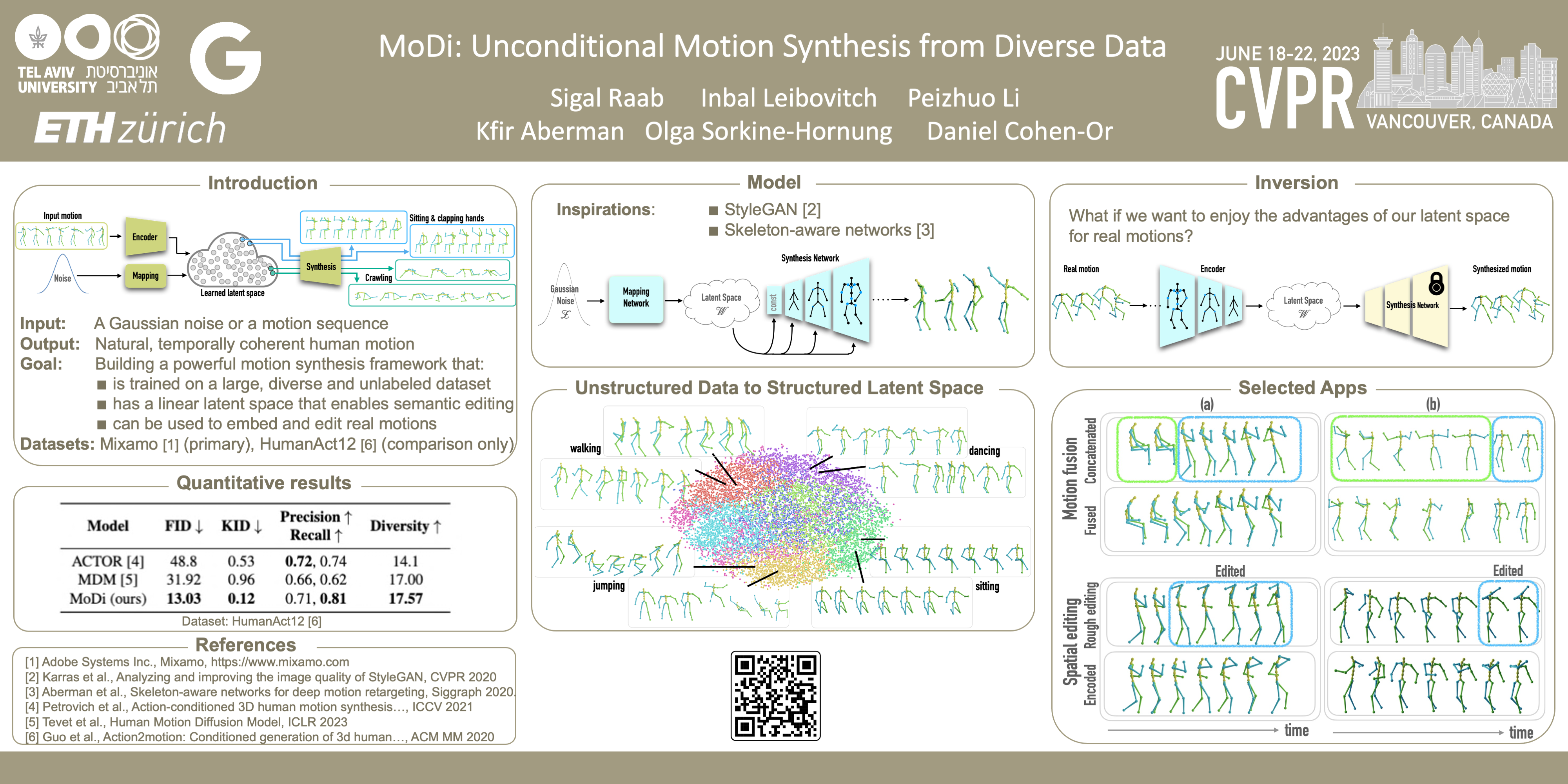
The emergence of neural networks has revolutionized the field of motion synthesis. Yet, learning to unconditionally synthesize motions from a given distribution remains challenging, especially when the motions are highly diverse. In this work, we present MoDi -- a generative model trained in an unsupervised setting from an extremely diverse, unstructured and unlabeled dataset. During inference, MoDi can synthesize high-quality, diverse motions. Despite the lack of any structure in the dataset, our model yields a well-behaved and highly structured latent space, which can be semantically clustered, constituting a strong motion prior that facilitates various applications including semantic editing and crowd animation. In addition, we present an encoder that inverts real motions into MoDi’s natural motion manifold, issuing solutions to various ill-posed challenges such as completion from prefix and spatial editing. Our qualitative and quantitative experiments achieve state-of-the-art results that outperform recent SOTA techniques. Code and trained models are available at https://sigal-raab.github.io/MoDi.