Self-Positioning Point-Based Transformer for Point Cloud Understanding
{kind=link}
Abstract
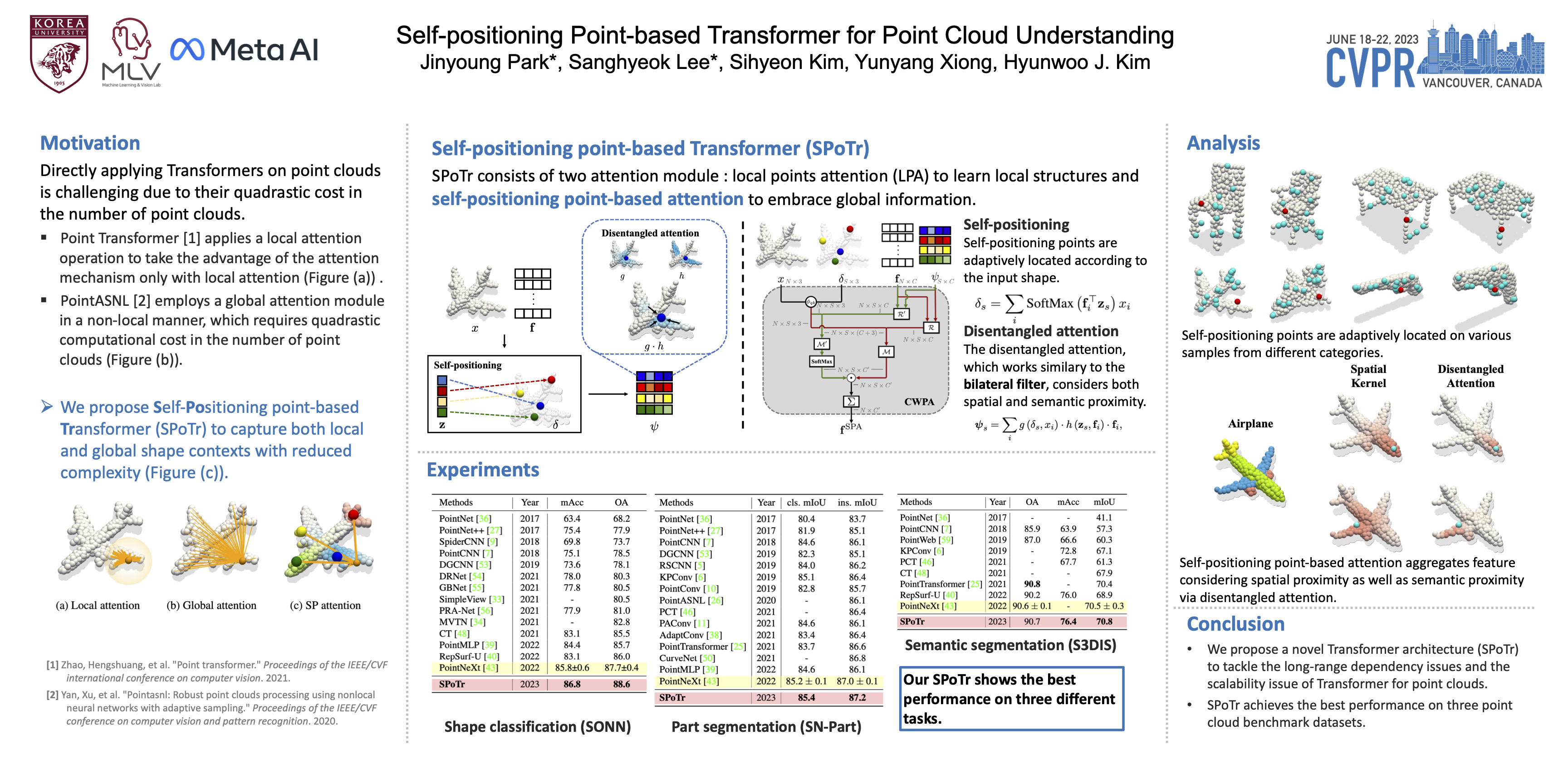
Transformers have shown superior performance on various computer vision tasks with their capabilities to capture long-range dependencies. Despite the success, it is challenging to directly apply Transformers on point clouds due to their quadratic cost in the number of points. In this paper, we present a Self-Positioning point-based Transformer (SPoTr), which is designed to capture both local and global shape contexts with reduced complexity. Specifically, this architecture consists of local self- attention and self-positioning point-based global cross-attention. The self-positioning points, adaptively located based on the input shape, consider both spatial and semantic information with disentangled attention to improve expressive power. With the self-positioning points, we propose a novel global cross-attention mechanism for point clouds, which improves the scalability of global self-attention by allowing the attention module to compute attention weights with only a small set of self-positioning points. Experiments show the effectiveness of SPoTr on three point cloud tasks such as shape classification, part segmentation, and scene segmentation. In particular, our proposed model achieves an accuracy gain of 2.6% over the previous best models on shape classification with ScanObjectNN. We also provide qualitative analyses to demonstrate the interpretability of self-positioning points. The code of SPoTr is available at https://github.com/mlvlab/SPoTr.