FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation
{kind=link}
Abstract
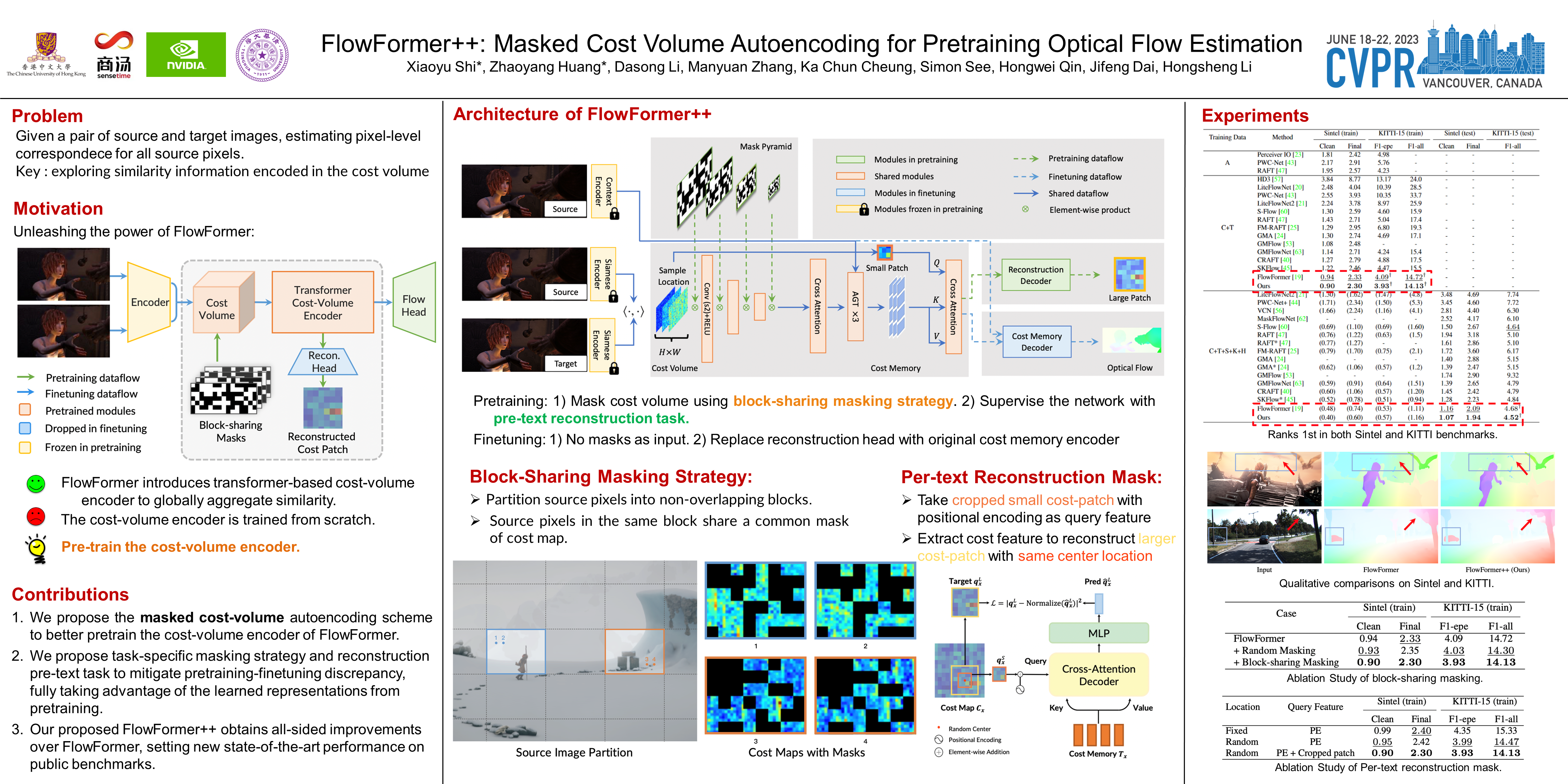
FlowFormer introduces a transformer architecture into optical flow estimation and achieves state-of-the-art performance. The core component of FlowFormer is the transformer-based cost-volume encoder. Inspired by recent success of masked autoencoding (MAE) pretraining in unleashing transformers’ capacity of encoding visual representation, we propose Masked Cost Volume Autoencoding (MCVA) to enhance FlowFormer by pretraining the cost-volume encoder with a novel MAE scheme. Firstly, we introduce a block-sharing masking strategy to prevent masked information leakage, as the cost maps of neighboring source pixels are highly correlated. Secondly, we propose a novel pre-text reconstruction task, which encourages the cost-volume encoder to aggregate long-range information and ensures pretraining-finetuning consistency. We also show how to modify the FlowFormer architecture to accommodate masks during pretraining. Pretrained with MCVA, our proposed FlowFormer++ ranks 1st among published methods on both Sintel and KITTI-2015 benchmarks. Specifically, FlowFormer++ achieves 1.07 and 1.94 average end-point-error (AEPE) on the clean and final pass of Sintel benchmark, leading to 7.76% and 7.18% error reductions from FlowFormer. FlowFormer++ obtains 4.52 F1-all on the KITTI-2015 test set, improving FlowFormer by 0.16.