Detecting Everything in the Open World: Towards Universal Object Detection
{kind=link}
Abstract
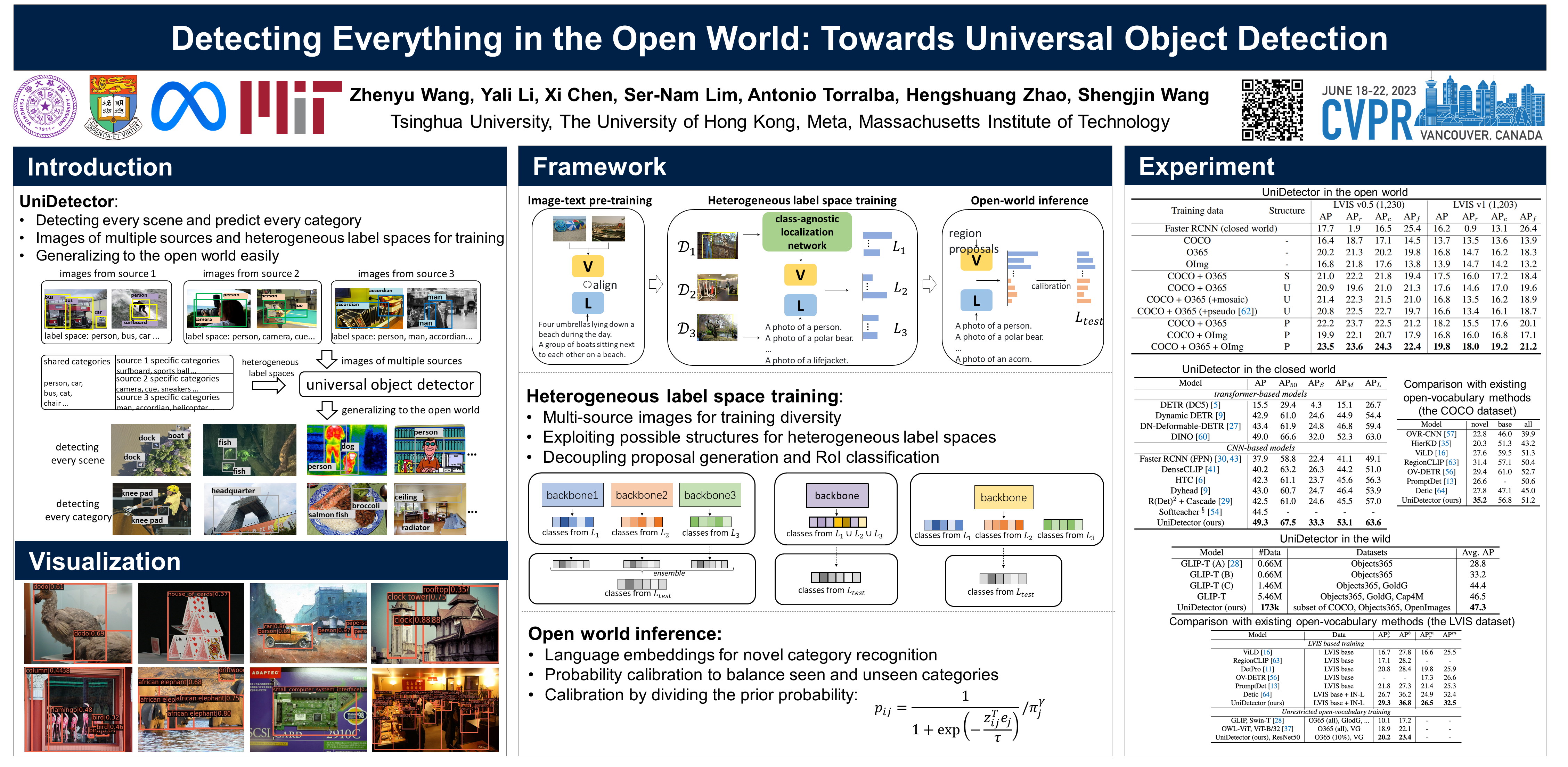
In this paper, we formally address universal object detection, which aims to detect every scene and predict every category. The dependence on human annotations, the limited visual information, and the novel categories in the open world severely restrict the universality of traditional detectors. We propose UniDetector, a universal object detector that has the ability to recognize enormous categories in the open world. The critical points for the universality of UniDetector are: 1) it leverages images of multiple sources and heterogeneous label spaces for training through the alignment of image and text spaces, which guarantees sufficient information for universal representations. 2) it generalizes to the open world easily while keeping the balance between seen and unseen classes, thanks to abundant information from both vision and language modalities. 3) it further promotes the generalization ability to novel categories through our proposed decoupling training manner and probability calibration. These contributions allow UniDetector to detect over 7k categories, the largest measurable category size so far, with only about 500 classes participating in training. Our UniDetector behaves the strong zero-shot generalization ability on large-vocabulary datasets like LVIS, ImageNetBoxes, and VisualGenome - it surpasses the traditional supervised baselines by more than 4% on average without seeing any corresponding images. On 13 public detection datasets with various scenes, UniDetector also achieves state-of-the-art performance with only a 3% amount of training data.