PeakConv: Learning Peak Receptive Field for Radar Semantic Segmentation
{kind=link}
Abstract
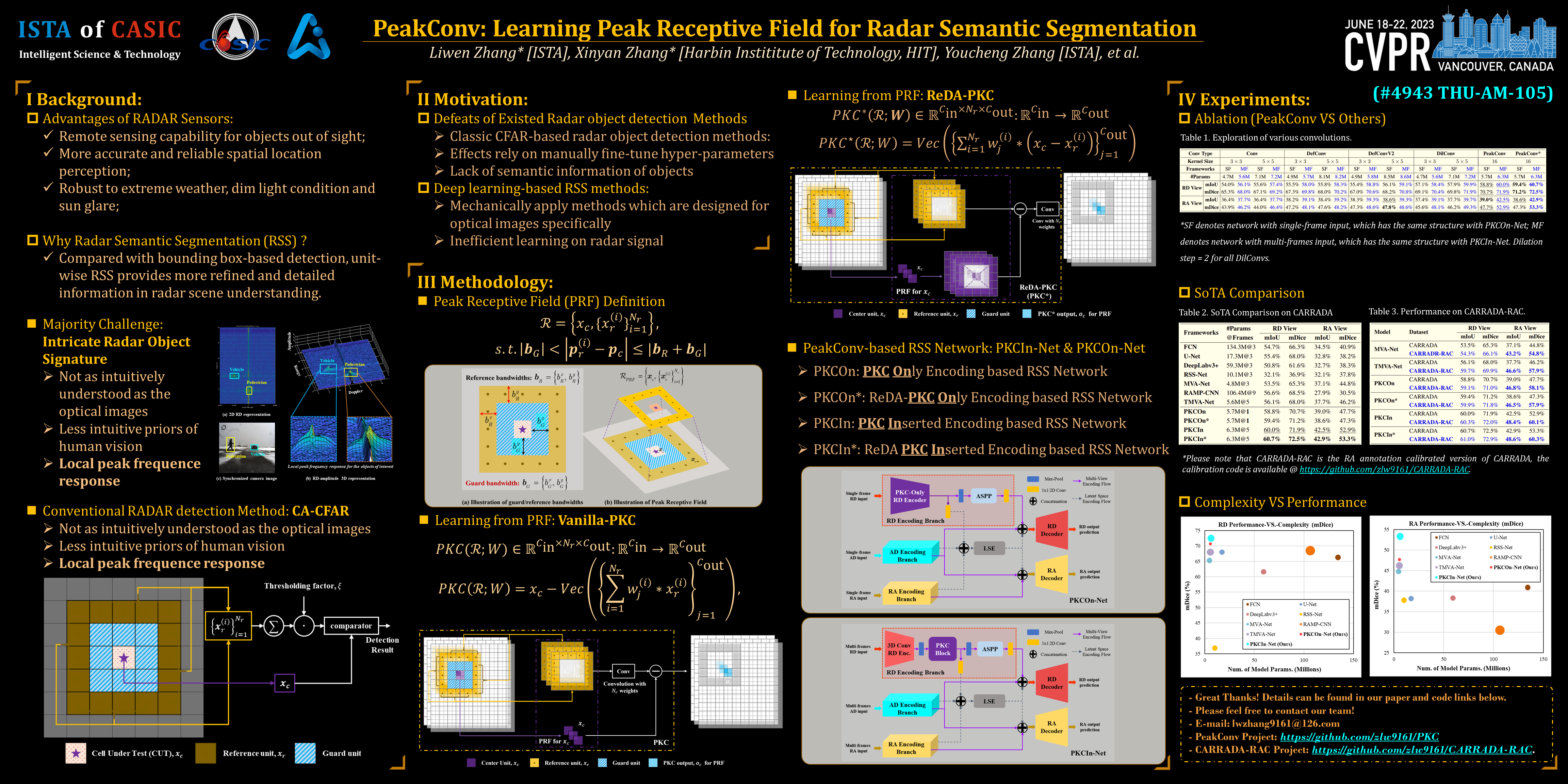
The modern machine learning-based technologies have shown considerable potential in automatic radar scene understanding. Among these efforts, radar semantic segmentation (RSS) can provide more refined and detailed information including the moving objects and background clutters within the effective receptive field of the radar. Motivated by the success of convolutional networks in various visual computing tasks, these networks have also been introduced to solve RSS task. However, neither the regular convolution operation nor the modified ones are specific to interpret radar signals. The receptive fields of existing convolutions are defined by the object presentation in optical signals, but these two signals have different perception mechanisms. In classic radar signal processing, the object signature is detected according to a local peak response, i.e., CFAR detection. Inspired by this idea, we redefine the receptive field of the convolution operation as the peak receptive field (PRF) and propose the peak convolution operation (PeakConv) to learn the object signatures in an end-to-end network. By incorporating the proposed PeakConv layers into the encoders, our RSS network can achieve better segmentation results compared with other SoTA methods on a multi-view real-measured dataset collected from an FMCW radar. Our code for PeakConv is available at https://github.com/zlw9161/PKC.