Conditional Generation of Audio From Video via Foley Analogies
{kind=link}
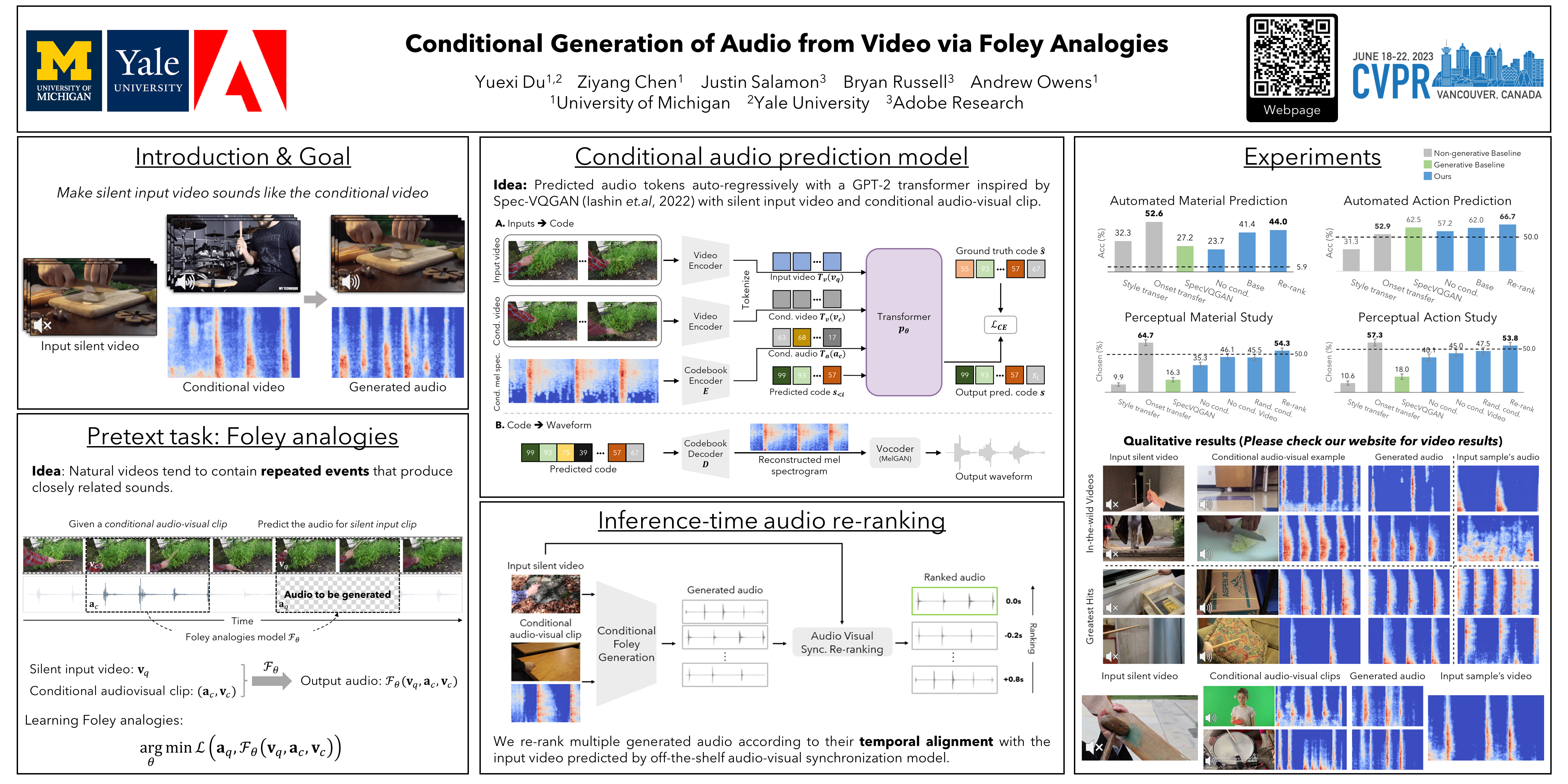
Abstract
The sound effects that designers add to videos are designed to convey a particular artistic effect and, thus, may be quite different from a scene’s true sound. Inspired by the challenges of creating a soundtrack for a video that differs from its true sound, but that nonetheless matches the actions occurring on screen, we propose the problem of conditional Foley. We present the following contributions to address this problem. First, we propose a pretext task for training our model to predict sound for an input video clip using a conditional audio-visual clip sampled from another time within the same source video. Second, we propose a model for generating a soundtrack for a silent input video, given a user-supplied example that specifies what the video should “sound like”. We show through human studies and automated evaluation metrics that our model successfully generates sound from video, while varying its output according to the content of a supplied example.