Towards Generalisable Video Moment Retrieval: Visual-Dynamic Injection to Image-Text Pre-Training
{kind=link}
Abstract
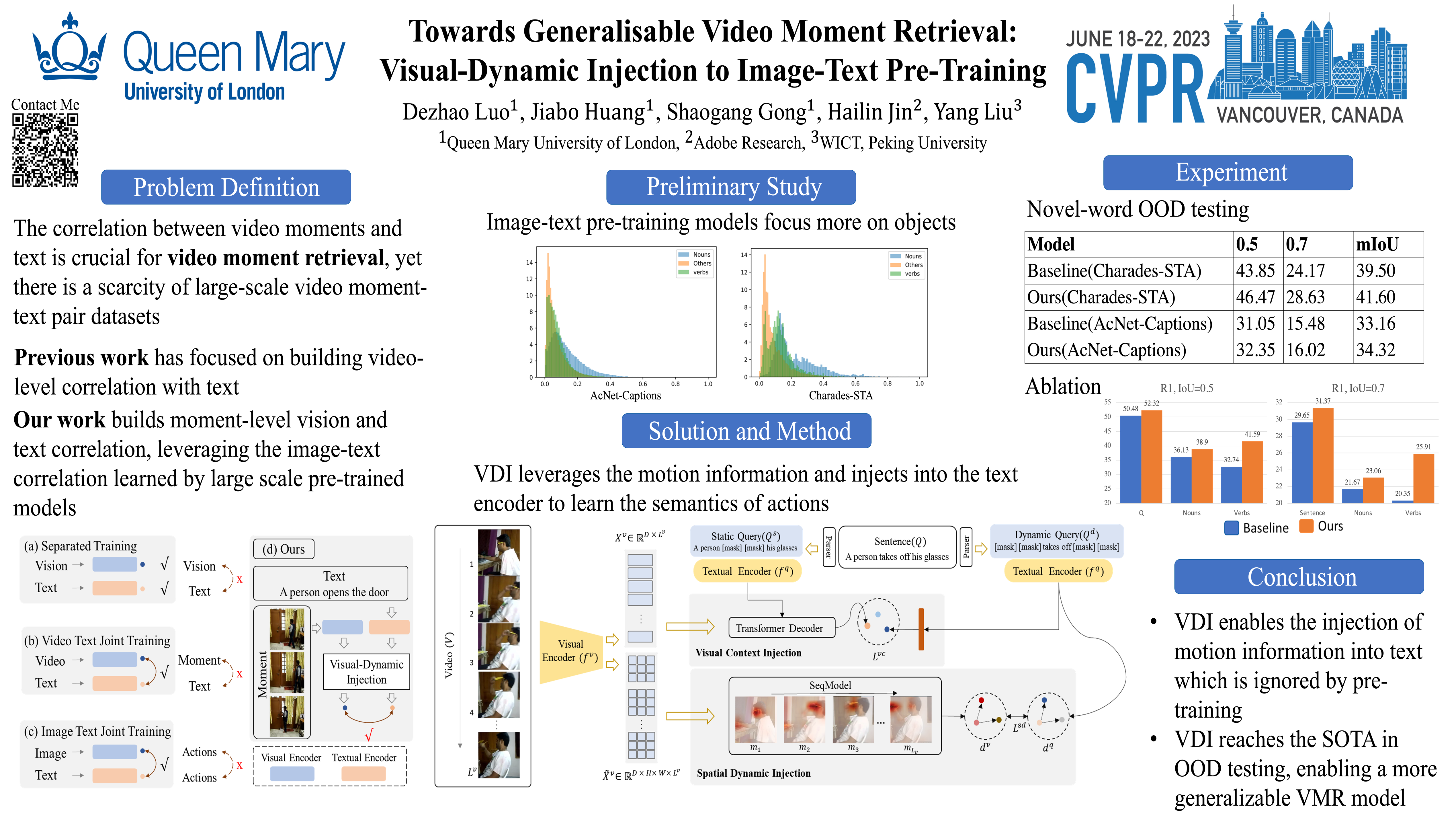
The correlation between the vision and text is essential for video moment retrieval (VMR), however, existing methods heavily rely on separate pre-training feature extractors for visual and textual understanding. Without sufficient temporal boundary annotations, it is non-trivial to learn universal video-text alignments. In this work, we explore multi-modal correlations derived from large-scale image-text data to facilitate generalisable VMR. To address the limitations of image-text pre-training models on capturing the video changes, we propose a generic method, referred to as Visual-Dynamic Injection (VDI), to empower the model’s understanding of video moments. Whilst existing VMR methods are focusing on building temporal-aware video features, being aware of the text descriptions about the temporal changes is also critical but originally overlooked in pre-training by matching static images with sentences. Therefore, we extract visual context and spatial dynamic information from video frames and explicitly enforce their alignments with the phrases describing video changes (e.g. verb). By doing so, the potentially relevant visual and motion patterns in videos are encoded in the corresponding text embeddings (injected) so to enable more accurate video-text alignments. We conduct extensive experiments on two VMR benchmark datasets (Charades-STA and ActivityNet-Captions) and achieve state-of-the-art performances. Especially, VDI yields notable advantages when being tested on the out-of-distribution splits where the testing samples involve novel scenes and vocabulary.