Unsupervised 3D Point Cloud Representation Learning by Triangle Constrained Contrast for Autonomous Driving
{kind=link}
Abstract
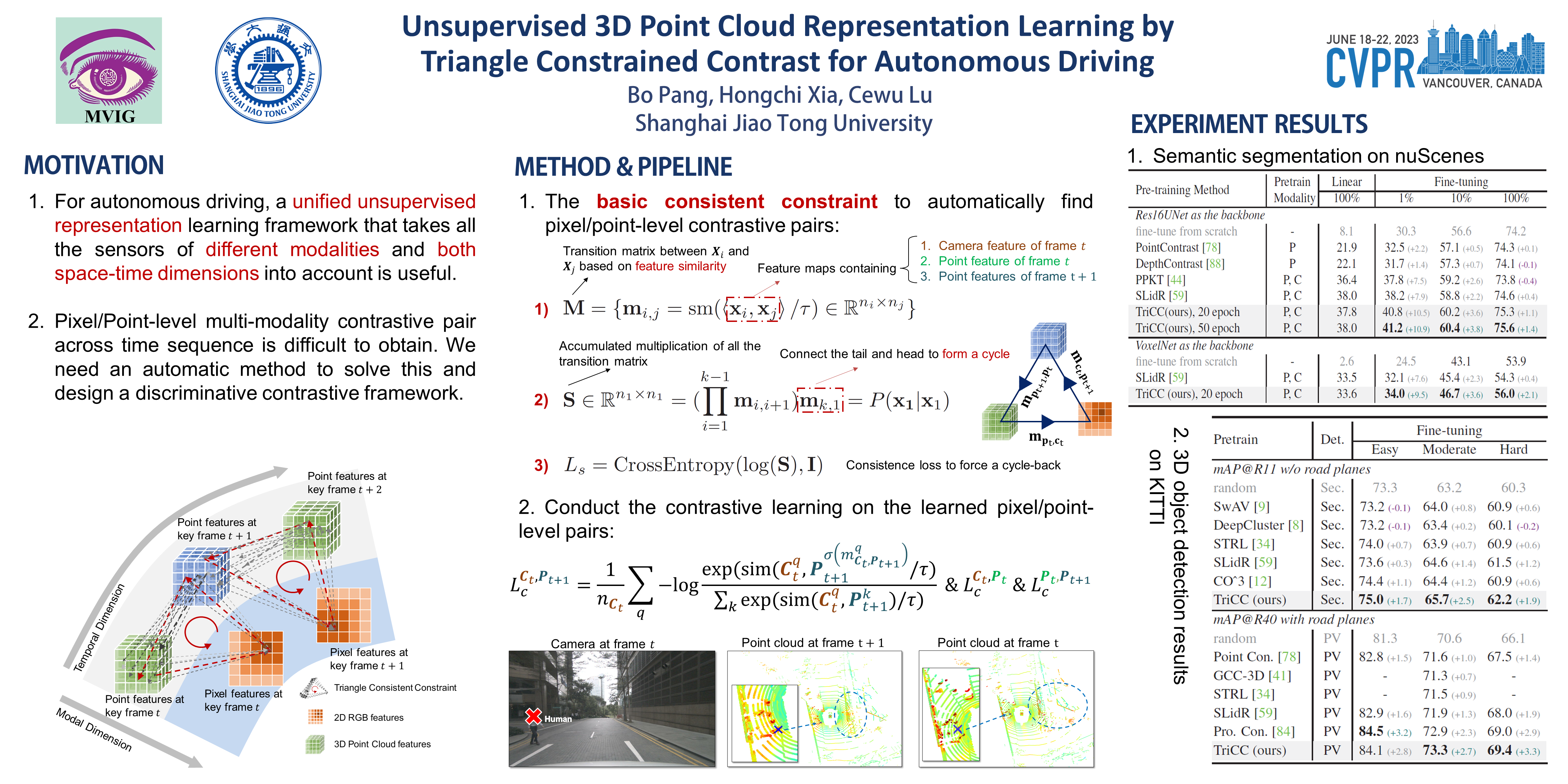
Due to the difficulty of annotating the 3D LiDAR data of autonomous driving, an efficient unsupervised 3D representation learning method is important. In this paper, we design the Triangle Constrained Contrast (TriCC) framework tailored for autonomous driving scenes which learns 3D unsupervised representations through both the multimodal information and dynamic of temporal sequences. We treat one camera image and two LiDAR point clouds with different timestamps as a triplet. And our key design is the consistent constraint that automatically finds matching relationships among the triplet through “self-cycle” and learns representations from it. With the matching relations across the temporal dimension and modalities, we can further conduct a triplet contrast to improve learning efficiency. To the best of our knowledge, TriCC is the first framework that unifies both the temporal and multimodal semantics, which means it utilizes almost all the information in autonomous driving scenes. And compared with previous contrastive methods, it can automatically dig out contrasting pairs with higher difficulty, instead of relying on handcrafted ones. Extensive experiments are conducted with Minkowski-UNet and VoxelNet on several semantic segmentation and 3D detection datasets. Results show that TriCC learns effective representations with much fewer training iterations and improves the SOTA results greatly on all the downstream tasks. Code and models can be found at https://bopang1996.github.io/.