Catch Missing Details: Image Reconstruction With Frequency Augmented Variational Autoencoder
{kind=link}
Abstract
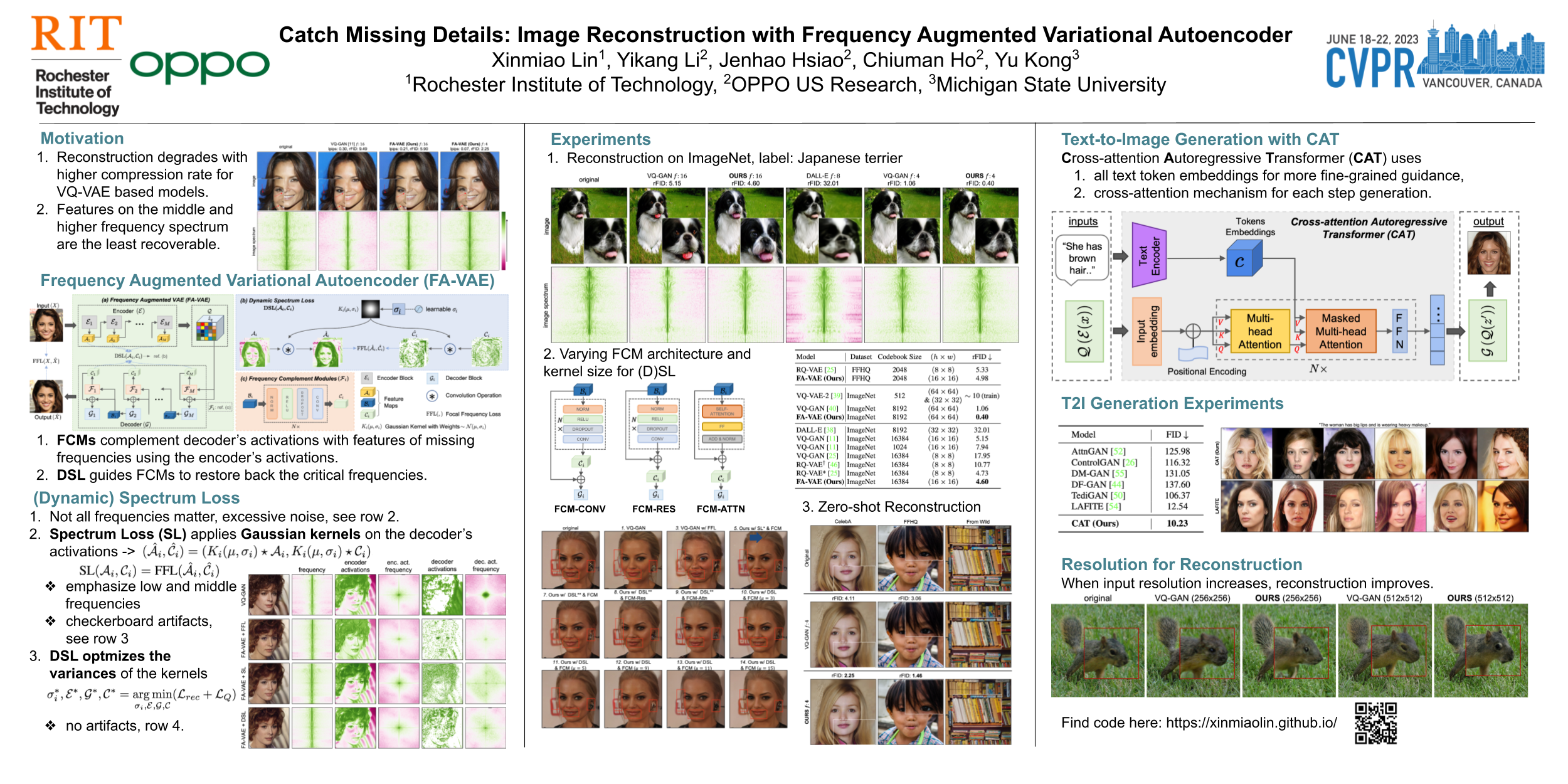
The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum, which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequancy Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.