Seeing a Rose in Five Thousand Ways
{kind=link}
Abstract
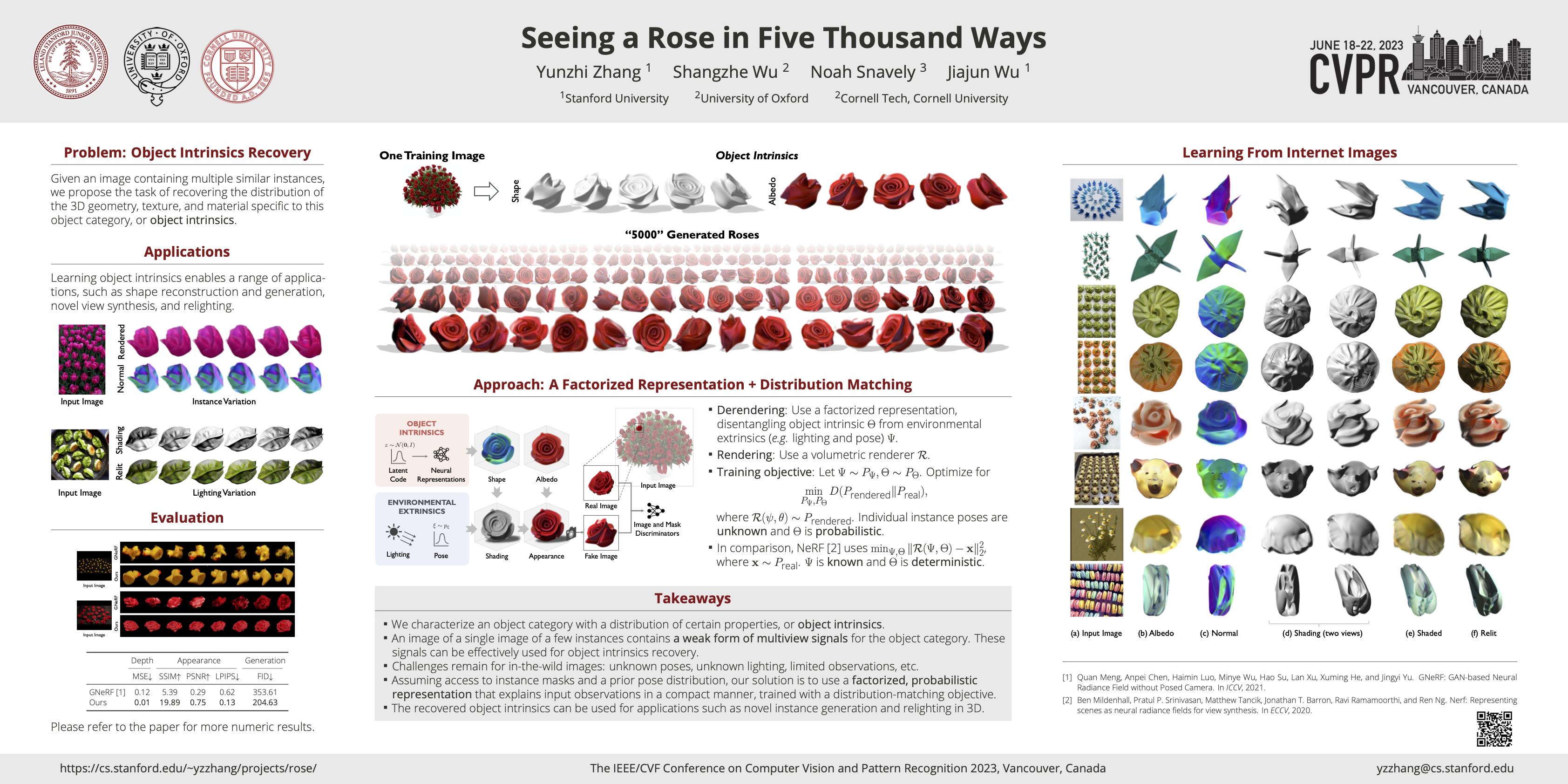
What is a rose, visually? A rose comprises its intrinsics, including the distribution of geometry, texture, and material specific to its object category. With knowledge of these intrinsic properties, we may render roses of different sizes and shapes, in different poses, and under different lighting conditions. In this work, we build a generative model that learns to capture such object intrinsics from a single image, such as a photo of a bouquet. Such an image includes multiple instances of an object type. These instances all share the same intrinsics, but appear different due to a combination of variance within these intrinsics and differences in extrinsic factors, such as pose and illumination. Experiments show that our model successfully learns object intrinsics (distribution of geometry, texture, and material) for a wide range of objects, each from a single Internet image. Our method achieves superior results on multiple downstream tasks, including intrinsic image decomposition, shape and image generation, view synthesis, and relighting.