CPGA: Coding Priors-Guided Aggregation Network for Compressed Video Quality Enhancement
{kind=link}
Abstract
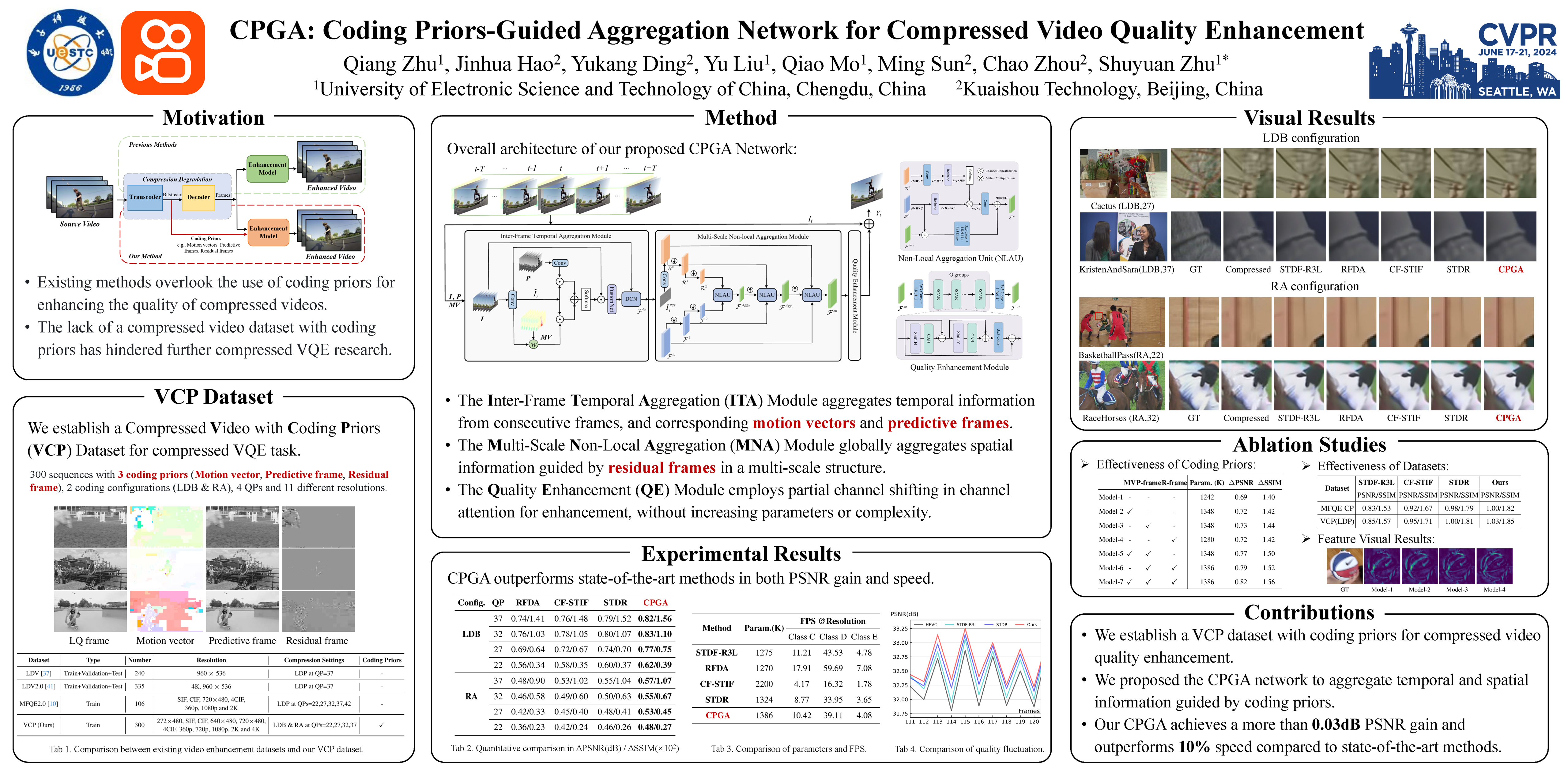
Recently, numerous approaches have achieved notable success in compressed video quality enhancement (VQE). However, these methods usually ignore the utilization of valuable coding priors inherently embedded in compressed videos, such as motion vectors and residual frames, which carry abundant temporal and spatial information. To remedy this problem, we propose the Coding Priors-Guided Aggregation (CPGA) network to utilize temporal and spatial information from coding priors. The CPGA mainly consists of an inter-frame temporal aggregation (ITA) module and a multi-scale non-local aggregation (MNA) module. Specifically, the ITA module aggregates temporal information from consecutive frames and coding priors, while the MNA module globally captures spatial information guided by residual frames. In addition, to facilitate research in VQE task, we newly construct the Video Coding Priors (VCP) dataset, comprising 300 videos with various coding priors extracted from corresponding bitstreams. It remedies the shortage of previous datasets on the lack of coding information. Experimental results demonstrate the superiority of our method compared to existing state-of-the-art methods. The code and dataset will be released at https://github.com/VQE-CPGA/CPGA.