Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection
{kind=link}
Abstract
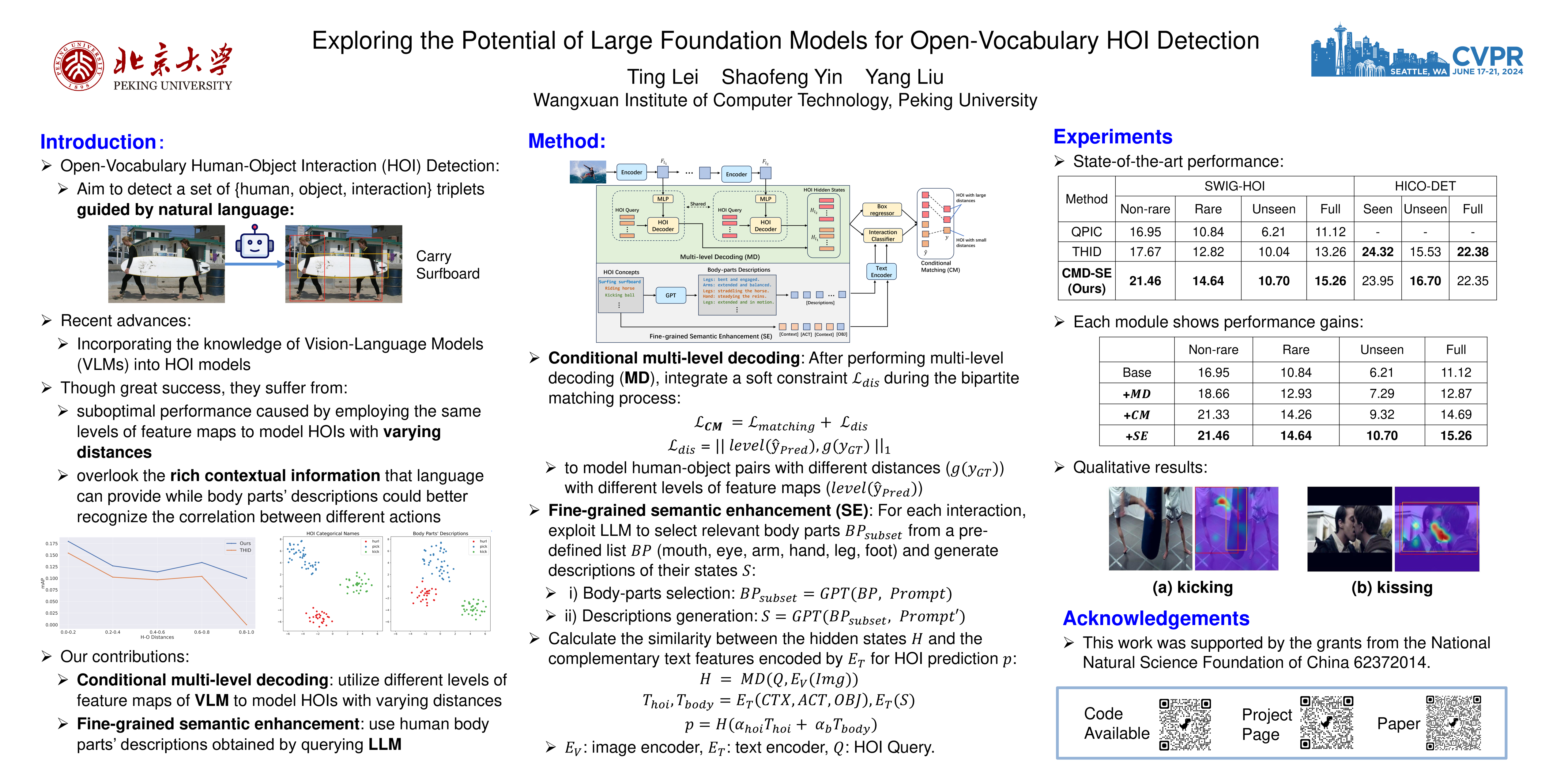
Open-vocabulary human-object interaction (HOI) detection, which is concerned with the problem of detecting novel HOIs guided by natural language, is crucial for understanding human-centric scenes. However, prior zero-shot HOI detectors often employ the same levels of feature maps to model HOIs with varying distances, leading to suboptimal performance in scenes containing human-object pairs with a wide range of distances.In addition, these detectors primarily rely on category names and overlook the rich contextual information that language can provide, which is essential for capturing open vocabulary concepts that are typically rare and not well-represented by category names alone.In this paper, we introduce a novel end-to-end open vocabulary HOI detection framework with conditional multi-level decoding and fine-grained semantic enhancement~(CMD-SE), harnessing the potential of Visual-Language Models (VLMs). Specifically, we propose to model human-object pairs with different distances with different levels of feature maps by incorporating a soft constraint during the bipartite matching process. Furthermore, by leveraging large language models (LLMs) such as GPT models, we exploit their extensive world knowledge to generate descriptions of human body part states for various interactions. Then we integrate the generalizable and fine-grained semantics of human body parts to improve interaction recognition.Experimental results on two datasets, SWIG-HOI and HICO-DET, demonstrate that our proposed method achieves state-of-the-art results in open vocabulary HOI detection.